SCA Remediation at Scale: Dependencies Are the Real Challenge


77% of your code came from somewhere else. You didn't write it, you didn't review it, and you definitely didn't audit it for security vulnerabilities. You pulled it in with npm install or mvn dependency:resolve and moved on.
That was fine when supply chain attacks were rare. They aren't rare anymore. Supply chain attacks increased 567% between 2019 and 2024 (Sonatype State of the Software Supply Chain), and SCA scanners responded by generating more alerts than any other security tool category — 2-4x the volume of SAST findings.
But most of that output is noise. 88% of "Critical" dependency CVEs aren't actually critical in your environment. 60-80% of the vulnerable code paths in your dependency tree are never called by your application. 71% of organizations report that 21-60% of their scan results are worthless.
Your SCA scanner is working. Your teams are drowning in its output. And the vulnerability backlog keeps growing because nobody's solved the harder problem: actually fixing dependency vulnerabilities at scale.
Why Dependency Remediation Is Harder Than You Think
If you've fixed a SAST finding, you know the drill: change your code, run tests, ship. The vulnerability is in code you wrote, using patterns you understand.
SCA remediation doesn't work that way. The vulnerability lives in someone else's code. You can't patch it. You can only upgrade to a version where someone else patched it, and that upgrade carries risks that first-party code changes don't.
The transitive dependency problem. 77% of your dependency tree is indirect, your dependencies' dependencies' dependencies. A vulnerability three layers deep in a transitive chain means you need to trace back to the direct dependency you actually control, figure out which version resolves the transitive vulnerability, and verify the entire chain is consistent. Try doing that manually across 500 repositories.
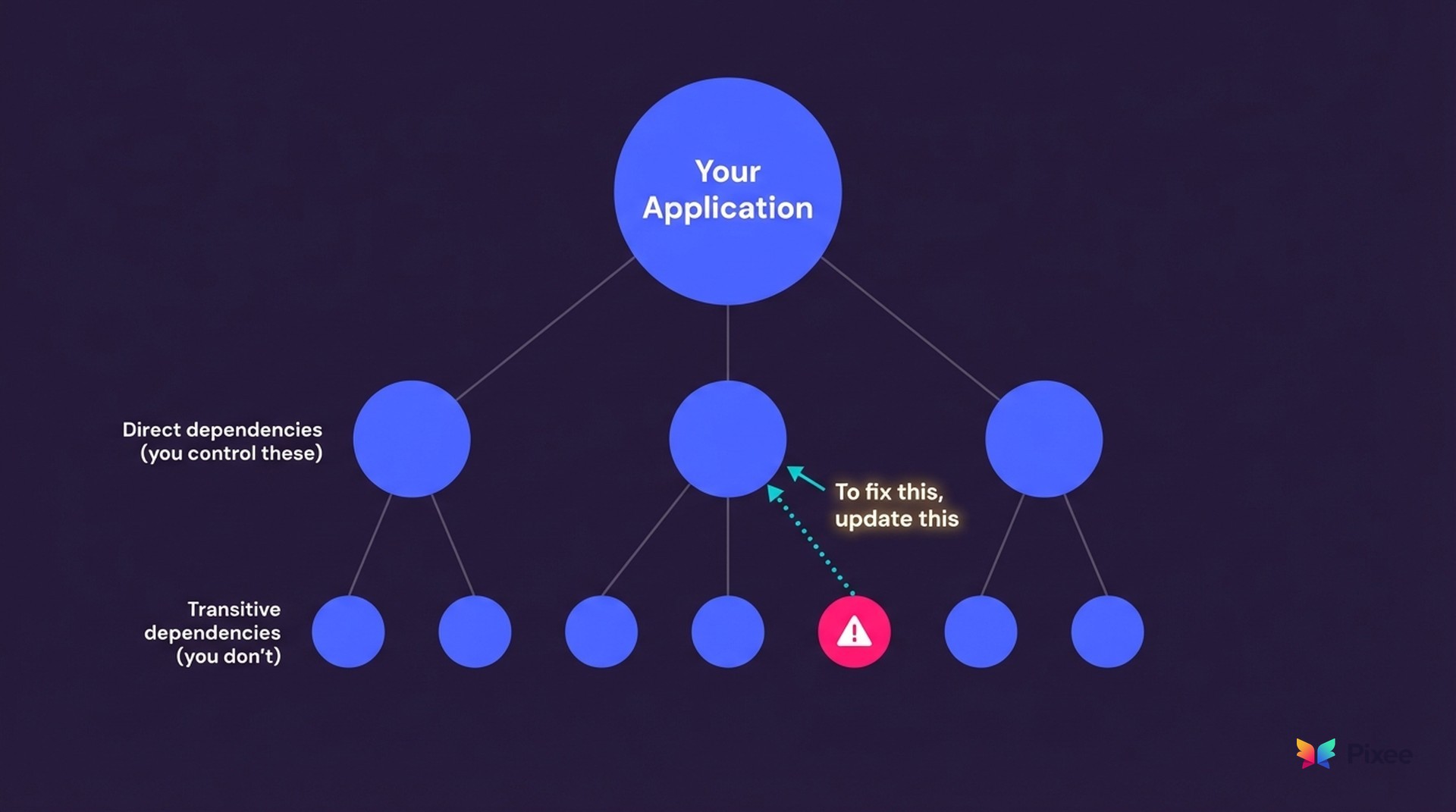
Version bumping isn't vulnerability fixing. Tools like Dependabot and Renovate have trained teams to think "upgrade the version" equals "fix the vulnerability." It doesn't. A major version bump might resolve the CVE but introduce breaking API changes that cause production incidents. After a few broken builds from blind version bumps, developers stop trusting automated dependency PRs entirely. The alert fatigue that started with scanners extends to the remediation tools themselves.
Breaking change prediction is the missing capability. What you actually need before merging a dependency update is confidence, not hope, that the upgrade won't break anything. Will this version change modify the API surface your code calls? Does it remove a method you depend on? Does it change default behavior in a way that affects your application logic?
A global payments processor using automated remediation with breaking change prediction reported 80-90% confidence on safe dependency updates. Their developers could review an upgrade PR and know, before merging, whether it would break downstream services. That's the difference between "upgrade and pray" and "upgrade and ship."
As I wrote in "So, You Want to Build a Resolution Platform", SCA triage is distinctly harder than SAST triage because it requires call graph analysis, import path tracing, reachability verification, and version-specific vulnerability mapping, all simultaneously. Engineering leaders who've attempted internal builds consistently report costs exceeding $1M and timelines beyond 2 years before reaching production quality. Most of those internal tools become what Caleb Sima calls "zombie tools." The best engineers build it, get promoted, and leave.
The Triage Problem You Have to Solve First
Before you can fix dependency vulnerabilities, you have to figure out which ones actually matter. This is where most AppSec programs stall.
Across 102 companies and 395 documented pain instances we've analyzed, triage burden shows up 2.4x more frequently than remediation burden (126 vs 52 instances). A 14-person security team at a mid-market retailer supporting 500+ developers put it bluntly: "Those go back to us. We are not triaging those right now as much as we could be. Generally, it gets ignored."
That's not negligence. That's math. At a 1:35 security-to-developer ratio, manual triage is physically impossible.
We've written about the triage automation framework in depth elsewhere. For SCA specifically, two layers matter:
Reachability: Is the vulnerable function actually called by your code? Your app imports lodash, but does it ever call the vulnerable merge() function? For dependencies, this means tracing call paths through transitive chains. Not just checking whether the package exists in your lockfile, but whether the specific vulnerable code path is reachable from your application entry points. This alone eliminates 60-80% of dependency alerts.
Exploitability: Even if reachable, can it be exploited given your deployment context? A deserialization vulnerability in an internal microservice behind three auth layers and no public network exposure is a different risk than the same CVE in a public-facing API. This is the analysis that turns "87% run exploitable code" from a panic headline into actionable prioritization.
What makes SCA triage distinct from SAST triage is the transitive dimension. You're not just analyzing your code — you're analyzing call paths through libraries you didn't write, into sub-dependencies you didn't choose, looking for vulnerable functions that may be three layers removed from anything in your source tree. The combinatorial complexity is why manual dependency triage collapses at scale.
What Remediation at Scale Actually Requires
Once you've triaged down to vulnerabilities that are reachable, exploitable, and worth fixing, you need a remediation system that handles the realities of enterprise dependency management. Here's what that means in practice:
Scanner-agnostic ingestion. Your organization runs 5.3 security tools on average. Snyk for SCA, Checkmarx for SAST, maybe Veracode for compliance, plus SonarQube and GitHub Advanced Security. Your remediation platform can't be locked to one scanner's output. It needs to consume findings from 50+ tools via standardized formats like SARIF and normalize them into a single fix queue. Otherwise you're building a different remediation workflow for every scanner, which is just tool sprawl with extra steps.
Context-aware fixing. Generic dependency upgrades are the reason developers don't trust automated PRs. Purpose-built remediation understands your coding conventions, your validation libraries, your architectural patterns. When it upgrades a dependency, it adjusts your code to handle any API changes in the new version. The fix looks like something your team wrote, not something a bot generated.
Manifest-level resolution. SCA fixes happen at the package manifest level — package.json, pom.xml, requirements.txt, go.mod. The system needs to resolve transitive chains from the root, handling version constraint conflicts across your dependency tree. Fixing a transitive vulnerability often means updating a direct dependency to a version whose own dependency tree no longer includes the vulnerable package.
Developer-reviewable pull requests. Fixes arrive as PRs that developers review, not as black-box patches applied to production. Developers are the reviewer, not the author. They evaluate the proposed fix against their understanding of the codebase, run their test suites, and merge with confidence.
Merge rate as the truth metric. This is the number that tells you whether automated remediation actually works: what percentage of generated fixes do developers accept and merge? Pixee's internal measurement shows a 76% merge rate across 100,000+ pull requests at 50+ companies. Three out of four fixes ship to production without modification. We publish this number because we think every remediation vendor should. So far, none have.
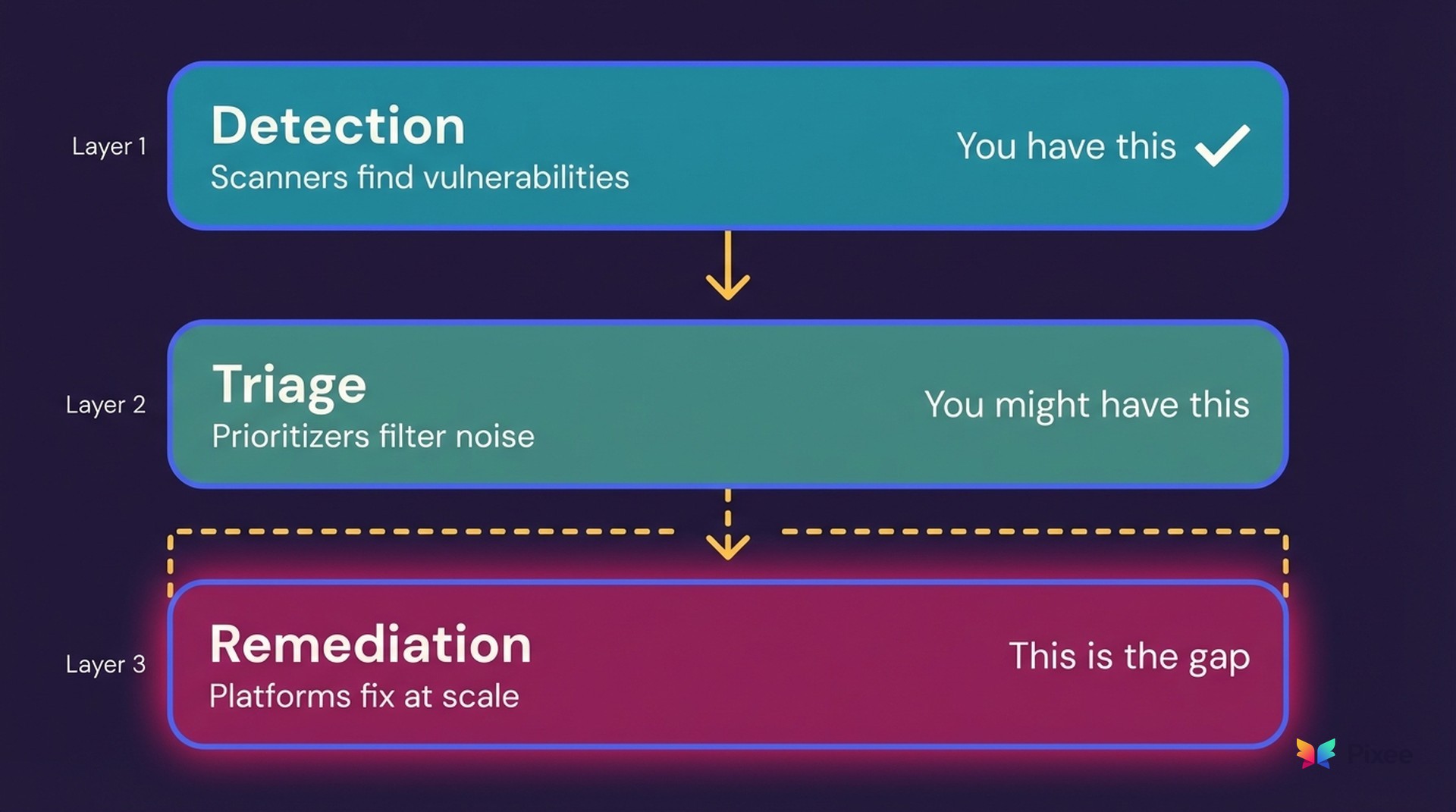
The Gap Between Detection and Resolution
Keep your scanner. Seriously. The software supply chain security market has excellent detection tools, and they keep getting better. Snyk's vulnerability database is comprehensive. Endor Labs' function-level reachability analysis genuinely cuts noise by 92%. Socket catches malicious packages that other tools miss. Mend and Renovate have version bumping automation down to a science.
The gap isn't in detection. It's in what happens after detection.
Every SCA tool in the market produces findings. Reachability tools prioritize those findings. Version bumping tools attempt upgrades. But none of them close the loop with production-ready, context-aware fixes that developers actually merge. Closing that loop requires understanding your codebase's conventions, predicting breaking changes, resolving transitive chains, and generating pull requests that pass code review.
This is why the best security architecture is best-of-breed detection combined with scanner-agnostic remediation. Your Snyk subscription gets more valuable when findings don't just create tickets but create AI-validated fixes that ship. Your Endor Labs investment pays off faster when reachable vulnerabilities get remediated the same week they're identified, not 252 days later.
The complementary model works because each layer does what it's best at. Scanners find. Prioritizers triage. Remediation platforms fix. You already have the first two. The third is the missing piece.
From 252 Days to Same-Day
The industry's mean time to remediation is 252 days. Here's what that timeline actually looks like for a dependency vulnerability:
Scanner finds CVE on Monday. Ticket created, assigned to the backlog. Three weeks later, a developer picks it up. They spend two hours investigating the dependency tree, determining which direct dependency to update, checking for breaking changes. They attempt the upgrade, tests fail, they revert. The ticket goes back to the backlog. Four months later, someone tries again. Maybe it gets fixed. Maybe time-to-exploit has collapsed and attackers got there first.
With automated SCA remediation, the workflow compresses:
Scanner finds CVE. Reachability analysis confirms the vulnerable function is called. Exploitability analysis confirms it's attackable in your deployment context. The system generates a fix at the manifest level with breaking change prediction, creates a PR with full context on what changed and why, and the developer reviews and merges — same day.
Not every vulnerability resolves this cleanly. Some require architectural changes, manual intervention, or coordinated upgrades across services. But the majority of dependency CVEs fall into well-understood patterns: straightforward version upgrades, transitive chain resolutions, known vulnerability remediation templates. Automation handles the bulk of them without human authorship.
The 81% of teams that knowingly ship vulnerable code aren't negligent. They're overwhelmed. They're triaging thousands of alerts with a handful of engineers, and the budget-backlog disconnect means hiring won't close the gap. Automation is the only math that works.
When remediation is automated, your AppSec team stops grooming backlogs and starts doing strategic security architecture. That's the actual ROI — not just faster fixes, but reclaimed capacity for the work that requires human judgment.
See It On Your Code
The only way to evaluate automated SCA remediation is to run it against your repositories — your dependency tree, your vulnerability backlog, your coding conventions.
See how Pixee remediates dependency vulnerabilities at scale →
Triage and remediation, together. That's what closes the gap between finding vulnerabilities and actually fixing them.
Related Reading
JavaScript supply chain security gap