AI Code Security Fixes: Three Gaps You Can't Prompt Your Way Around


Forty-two percent of enterprise coding workloads now run through AI assistants. These tools write features, refactor code, generate tests. They're genuinely useful. And increasingly, teams are expecting them to deliver AI code security fixes too.
That instinct makes sense on the surface. If Claude Code or Copilot can write complex application logic, surely it can fix a SQL injection. But this week's news should give you pause. Attackers jailbroke Claude and ChatGPT to breach Mexican government systems, stealing 150GB of data from 195 million taxpayer records. Separately, a vulnerability in OpenClaw (CVE-2026-25253) let malicious websites hijack locally running AI agents through unprotected WebSocket connections. AI coding assistants now hold CI/CD-equivalent privileges with none of the CI/CD controls.
The question isn't whether AI should play a role in security. It should. The question is whether a tool optimized for code generation can solve a problem that requires vulnerability elimination. Code generation and vulnerability remediation share a surface similarity — both produce code — but the constraints, validation requirements, and integration surfaces are structurally different. That gap explains why AI code security fixes from general-purpose tools fail most of the time, and why closing it requires architectural decisions that go beyond model selection.
Why AI Code Security Fixes Require More Than Code Generation
General-purpose AI coding tools optimize for speed, flexibility, and broad applicability. You describe what you want, the model writes code. That optimization target produces excellent results for feature development.
Security remediation requires a different set of capabilities: ingesting findings from multiple scanners (or AI SAST/other exploitability tooling), analyzing whether those findings are actually exploitable, generating fixes that match your specific codebase conventions, and tracking everything for compliance auditors. The optimization target isn't "write code fast." It's "eliminate vulnerabilities without breaking things, at scale, with an audit trail."
Checkmarx analyzed this gap after Claude Code Security launched, concluding that AI-generated code demands enterprise-grade, agentic AppSec at scale. CodeRabbit's research across hundreds of open-source projects found that AI code "looks fine until the review starts", with quality gaps emerging under scrutiny that surface-level generation can't detect.
The merge rate tells the story. In our deployments at Pixee, purpose-built security systems achieve a 76% merge rate across production environments. General-purpose AI tools typically land around 15-25% for security fixes in our observations and customer reports. Both use the same frontier language models. The gap is architectural, not about model quality. We'd welcome independent benchmarks on this — the comparison deserves rigorous third-party measurement.
Three Gaps You Can't Prompt Your Way Around
If you've tried using a general-purpose AI tool for security work, you've likely bumped into one or more of these. They're not limitations that better prompting fixes. They're structural.
Gap 1: Zero Scanner Integration
You run Snyk, Veracode, maybe Checkmarx or SonarQube. Probably several of these. The average security team manages 5.3 scanning tools, each with its own finding format, severity taxonomy, and deduplication logic. Your vulnerability backlog lives across all of them.
General-purpose AI can't see any of it. There's no mechanism to ingest findings from your security scanners, no concept of a "vulnerability backlog," no way to process 50,000 findings systematically. If you want a fix, someone has to manually identify the vulnerability, copy it into a terminal, and ask for a suggestion. One at a time.
Consider what that workflow looks like at scale. A developer opens Snyk, finds a high-severity finding, copies the vulnerability description, opens their AI assistant, pastes it in with relevant code context, evaluates the suggestion, and decides whether to apply it. That's 10-15 minutes per finding when everything goes well. Multiply by the backlog. Even if only 20% of your findings deserve attention, 10,000 real vulnerabilities at 15 minutes each is 2,500 engineer-hours of manual copy-paste before a single line of remediation code ships.
That's not a remediation strategy. It's a full-time job for twelve engineers, and it still doesn't produce an audit trail.
Gap 2: Non-Deterministic Fix Quality
LLMs produce different outputs for the same input. For code generation, that variability is a feature — you want creative solutions to novel problems. For security, it's an accountability problem. When your SAST tool flags SQL injection, you need a consistent, auditable answer. Not "probably a true positive, but run it again to be sure."
This matters more than most teams initially realize. Compliance frameworks like SOC 2, PCI-DSS, and SOX require demonstrable controls with reproducible outcomes. If an auditor asks "how do you remediate SQL injection findings?" and the answer is "we ask an LLM, which gives different suggestions each time," that's not a control. It's a hope. Regulated enterprises need fixes that produce the same output for the same finding class, every time, with a paper trail connecting the finding to the fix to the merge. This can still be achieved with an LLM authoring the fix, but it requires much more sophisticated guard-rails and context engineering.
The quality problem extends beyond individual fixes. The curl project ended its bug bounty program after being overwhelmed by low-quality, AI-generated vulnerability reports, a visible symptom of what happens when AI generates security assessments without validation gates. Without merge rate tracking, there's no quality feedback loop. You can't improve what you don't measure.
And then just for fun there's the irony: some of these tools have their own security vulnerabilities. Claude Code has had five documented CVEs in 2025-2026, including API key exfiltration and remote code execution. The tool being asked to fix your vulnerabilities has vulnerabilities.
Gap 3: No Triage Automation
Datadog's State of DevSecOps 2026 report found that 87% of organizations run at least one exploitable vulnerability in production, affecting 40% of services. Only 18% of vulnerabilities labeled "critical" remained critical once Datadog applied runtime context. Ninety-eight percent of .NET "critical" vulnerabilities were downgraded.
Your backlog is real. But a huge portion of it is false positives, and general-purpose AI has no way to distinguish real vulnerabilities from noise. No reachability analysis. No exploitability engine. No false positive filtering. Industry false positive rates run 71-88% across major scanners. Without triage, you're asking developers to fix findings that don't matter while real vulnerabilities sit untouched.
The downstream effect is corrosive. Developers learn to ignore security findings when the signal-to-noise ratio drops below a certain threshold. Once a team has been burned by three or four false positive "critical" findings in a row, they stop treating the next one as urgent. That's rational behavior from the developer's perspective and catastrophic from a security perspective. A general-purpose AI tool that generates fixes for untriaged findings doesn't solve this. It accelerates the trust erosion by producing more output from the same noisy input.
"We'll Build It Ourselves" Is Tempting
If general-purpose AI won't work, the next instinct is rational: "We have strong engineers. We're already using AI internally. We'll build our own."
I hear this pitch constantly. AI makes prototyping seductive. ChatGPT can write a vulnerability triage script in five minutes. But there's a well-documented gap between "working prototype" and "production-grade security platform," and research suggests 65% of software development costs materialize after deployment.
Our CTO and CoFounder, Arshan, wrote a full analysis of the build-vs-buy calculus for security remediation, but the short version: the accuracy bar is different in security than in other domains. At enterprise-scale backlogs, even 80% accuracy means thousands of wrong decisions per quarter. And internal builds face the organizational problem that Caleb Sima calls "zombie tools": the engineer who builds it gets promoted, the system enters maintenance mode, and within two years nobody wants to touch it.
Adam Schaal, a Pixee Distinguished Engineer, learned this firsthand. He led AWS SHINE, overseeing 14,000 security reviews per year, and built internal security automation at a scale most organizations can't replicate.
His conclusion after years of that work: "The security insight is the small part. The surrounding platform is the expensive part." The surrounding platform includes scanner normalization across different finding formats, deduplication logic, false positive tracking databases, fix validation pipelines, CI/CD integration for each customer environment, and compliance reporting. For most organizations, he argues, buying the foundation and customizing the triage and fix layer is the rational path.
That said, some teams do build successfully. If you have a dedicated platform team, a multi-year AI investment budget, and engineering leadership willing to commit 4+ FTEs indefinitely, the build path is credible. The key question isn't technical capability. It's organizational sustainability. Most organizations don't have the luxury of protecting a multi-year internal platform investment from competing priorities.
How Purpose-Built AI Security Automation Closes These Gaps
Full disclosure: what follows describes the architectural approach we built at Pixee, so take it with appropriate skepticism. Our perspective is informed but not neutral. We're sharing it because these architectural distinctions matter regardless of vendor, and because we'd rather you evaluate our reasoning openly than encounter it for the first time in a sales call.
The gaps above describe a triage-and-remediation problem, and closing them requires solving triage first. Purpose-built resolution platforms eliminate 95% of false positives through exploitability analysis before a single fix is generated. That solves the noise problem from Gap 3. Only then do architectural differences explain why the fixes that get generated actually get merged.
Three design choices drive the difference:
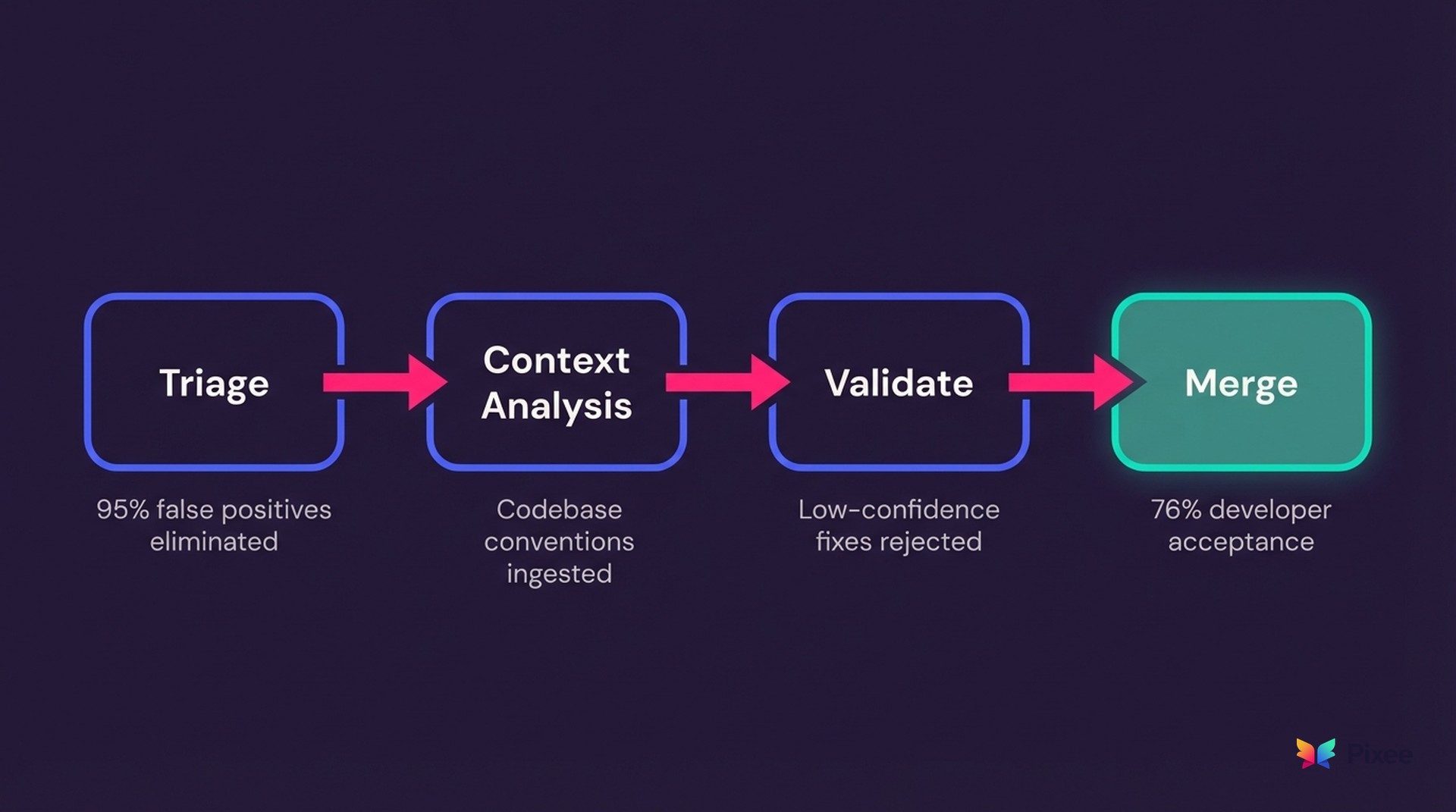
Contextual fix generation. The reason generic AI fixes fail code review is that they don't understand your environment. Purpose-built systems ingest your codebase conventions, security policies, and architectural patterns. The same SQL injection produces a different fix in a Spring Boot app with strict DAO layers than in a Flask prototype with raw queries. That contextual awareness is the difference between a fix that compiles and a fix your team actually merges.
Validation before developer review. Instead of sending every generated fix to a developer and hoping for the best, purpose-built systems add quality gates: automated checks reject low-confidence fixes before anyone sees them. Developers only review high-confidence candidates. Trust builds over time rather than eroding with each bad suggestion. I wrote a technical deep dive on how this validation architecture works if you want the engineering details.
Selective AI application. Most security triage decisions can combine deterministic fixes of narrow LLM guard-rails and paths. Certain reachability analysis, false positive pattern matching, and known-answer lookups are deterministic problems. An outdated dependency that's never imported doesn't need AI judgment — it needs a graph traversal. A SQL injection in a parameterized query doesn't need free-form reasoning — it needs pre-built pattern recognition. Scaffolding approaches and models lets you reserve deep AI reasoning for the genuinely complex cases (novel vulnerability patterns, architectural judgment calls) which can drop cost dramatically while processing enterprise-scale backlogs. Saving on vendor costs while running a seven-figure compute bill is not the way.
What to Ask Before You Decide
Whether you're evaluating a general-purpose tool, a purpose-built platform, or a build-it-yourself approach, these questions cut through positioning. Depending on your answers, the right choice might be any of the three.
One caveat: this landscape is evolving fast. General-purpose AI tools are shipping security-specific features quarterly. The structural gaps I've described may narrow over time. If you're reading this six months from now, re-evaluate. The distinctions matter today, but the moat is not permanent for anyone, including us.
AI Code Security Fixes Demand Purpose-Built Architecture
Every cybersecurity leader surveyed by Cycode reports AI generating code in their organization. That code creates security consequences at scale, with dependencies averaging 278 days out-of-date.
General-purpose AI excels at code generation. Purpose-built resolution platforms excel at vulnerability elimination, from triage that separates real risk from noise through remediation that developers actually trust to merge. Both categories are valid. The architecture is different because the problem is different.
The three gaps described here — scanner integration, deterministic quality, and triage automation — aren't feature requests waiting for the next product release. They reflect different optimization targets baked into the system architecture. A tool built to generate code fast has different data flows, validation layers, and feedback loops than a tool built to eliminate vulnerabilities reliably. Bolting security-specific features onto a code generation architecture is possible, and some vendors are doing it. Whether that approach closes the gaps or merely narrows them is a question your merge rate will answer empirically.
If you need code written faster, you have excellent options. If you need your vulnerability backlog triaged down to what matters and then fixed without breaking things, you need a purpose-built vulnerability remediation tool with different architecture. The merge rate tells you which you're getting.
Explore the Full Guide
This post is part of our automated remediation resource center resource center. Explore the full guide for frameworks, benchmarks, and implementation playbooks.
Related Reading
Google CodeMender validated autonomous remediation