So, You Want to Build a Resolution Platform


Building your own AI-powered vulnerability triage tool sounds reasonable. But if you've been through build vs. buy before, you know it's a minefield — one that will suck your team's time, energy, and cost more in dollars and opportunity costs than anyone budgeted for. AI makes it faster to prototype and way more tempting to try, but the realities that sunk internal builds in the past are still there. Especially when you're talking production-grade security.
Three things will sink you:
Eighty percent accuracy is catastrophic at scale. When your backlog has 100,000 findings, 80% accuracy means 20,000 wrong decisions. In security, that's 20,000 potential breaches you didn't catch, or 20,000 hours of developer time wasted chasing false positives. "Good enough" isn't good enough when your compliance auditor asks why a real vulnerability made it to production.
Your best engineer will build it, get promoted, and leave. Then what? Caleb Sima, who's invested in dozens of security companies including Contrast, Orca, and JupiterOne, calls these internal projects "zombie tools." Critical infrastructure that becomes unmaintained the moment its creator moves on. After a year, the model has drifted, the scanner integrations are stale, and you're stuck with something nobody wants to touch.
AI makes the easy part look trivial. ChatGPT can write a vulnerability triage script in five minutes. Making it production-ready (benchmark validation, multi-scanner support, model drift detection, continuous quality monitoring) takes years. Research shows 65% of AI development costs materialize after deployment. The prototype is the easy part.
I hear the build-it-ourselves pitch constantly. In sales calls, at conferences, in Slack DMs from engineering leaders. The instinct is rational: you have strong engineers, you're already using AI internally, and security automation doesn't seem that complicated from the outside.
Here's what I want to show you: exactly what you're signing up for.

Why the Temptation Is Stronger Than Ever
The temptation to build is real, and it's stronger now than it's ever been. LLMs have changed the calculus. Tasks that used to require specialized ML teams now seem accessible to any decent engineering org. "Just throw GPT at it" has become a legitimate first pass at problem-solving.
The pitch you're telling yourself probably sounds like one of these:
"We have budget for engineers, not SaaS." Headcount is approved. Software spend isn't. Building feels like using resources you already have.
"Our codebase is unique." Generic solutions won't understand your architecture, your frameworks, your conventions.
"We want full control." Security is core to your business. You can't depend on a vendor for something this critical.
"We already use LLMs internally — this can't be that hard." You have AI/ML expertise. Your team is already prompting GPT-4 for code generation. Vulnerability triage is just another classification problem, right?
Each is rational on the surface. What's underneath is an iceberg of complexity that makes "we'll build it" carry far more weight than it appears.
Why Security Is Different
This isn't like other build-vs-buy decisions.
Build-vs-buy frameworks often suggest building when something is "core to competitive advantage." A recommendation engine for a marketplace platform. Pricing optimization for a fintech. Predictive maintenance for industrial IoT.
Security remediation is not your competitive advantage. Your product is. Your customers don't buy from you because you have a well-tuned vulnerability triage system. They buy because of the features your engineers ship. Every engineer building security tooling is an engineer not building the thing that differentiates you in the market.
And security has unique constraints that make DIY harder than other domains:
Non-deterministic AI requires continuous validation. LLMs produce different outputs for the same input. In most contexts, this is manageable. In security, "it depends" creates accountability problems. When your SAST tool flags SQL injection, you need a consistent, auditable answer. Not "probably true positive, but run it again to be sure."
Vulnerability patterns evolve constantly. Log4Shell didn't exist, then it was everywhere. React2Shell dropped last week. Your training data is always incomplete. The benchmarks you built six months ago are already stale.
Scanner tools change. CodeQL's output format updates. Semgrep adds new rules. Your SCA vendor gets acquired and the product goes sideways. Every integration is maintenance overhead, forever.
Compliance requires audit trails. When the auditor asks "why did you mark this as a false positive?" you need evidence, not "the AI said so."
I published our entire benchmarking methodology so you can see what production-grade validation actually looks like. Pre-deployment testing against 15+ vulnerability classes. Monthly re-runs to detect model drift. Root cause analysis when accuracy degrades. Ask yourself: will your internal team maintain thousands of benchmark test cases? Re-run validation every time OpenAI updates GPT-4? We do. Every month.
The Enterprise IT Reality Check
The broader data on enterprise software projects is sobering.
McKinsey's 2024 research found that large IT projects run 45% over budget and 7% over schedule, while delivering 56% less value than predicted. Technical debt already consumes 20-40% of most organizations' technology estate value. Adding another internal tool means adding more debt.
The Standish Group's CHAOS report (2024) is even more direct: 35% of large custom software initiatives are abandoned entirely. Only 29% are delivered successfully by traditional measures.
This isn't hypothetical. These numbers are from organizations with strong engineering talent, clear requirements, and executive sponsorship. The same conditions you think you have.
Things Your Triage Won't Do
Let's get specific. Start with triage: the part that looks at scanner output and decides what's real and what's noise.
Investigation Depth
Your DIY triage will do basic filtering. It might even do it reasonably well for common patterns. But there's a depth of analysis that separates "good enough" from "actually useful."
Consider a vulnerability report flagging Apache Commons Lang's RandomStringUtils for weak random number generation. Surface-level triage either accepts the finding or ignores the class entirely.
Deep triage looks like this:
The output isn't just "false positive" or "true positive." It's a reasoning chain showing why, with specific code references, version numbers, and security control identification.
Building this depth means understanding not just vulnerability patterns, but how those patterns manifest differently across dependency versions, framework configurations, and coding styles. Not one model. Thousands of edge cases.
The SCA Triage Problem
SAST triage is hard. SCA triage is a different beast entirely.
When your SCA scanner flags a vulnerable dependency, the question isn't just "is this version vulnerable?" It's: does your code actually call the vulnerable function? Is the vulnerable code path reachable from your application's entry points? Does your deployment configuration expose the attack surface?
88% of SCA alerts aren't exploitable in the context of your application. Your DIY triage needs to determine exploitability by tracing call graphs, analyzing import paths, and understanding how your code interacts with each dependency. That requires deep program analysis — not pattern matching on CVE numbers.
And unlike SAST findings where the vulnerable code is yours, SCA findings sit in third-party code you don't control. The fix isn't "change this line." It's "upgrade this dependency without breaking your build, your API contracts, or your transitive dependency tree." Breaking change detection alone is a research project.
Exploitability Verification
Static analysis tells you something could be vulnerable. Exploitability verification tells you whether it actually is.
Take regex validation bypasses. A scanner flags a URL validation function as potentially bypassable. Your DIY triage sees "regex issue" and either accepts it or doesn't.
What you actually need:
This isn't theoretical. It's "here's the payload https://fonts.gstatic.com.evil.com and here's proof it passes your check." Or it's "we tested 500 bypass patterns and none worked. Likely a false positive."
This requires maintaining payload libraries, understanding evasion techniques across vulnerability classes, and running actual tests against code patterns. It's a research function masquerading as a feature.
Scanner-Specific Knowledge
Different scanners have different failure modes. CodeQL finds things Semgrep misses. Snyk has false positive patterns that Fortify doesn't. SonarQube flags code that isn't actually problematic in specific framework contexts.
Deep triage requires understanding what each scanner is actually detecting, not just what it claims to detect. When CodeQL says "SQL injection," is it looking at actual database calls or just pattern-matching on variable names?
This knowledge comes from analyzing thousands of findings across dozens of scanners, tracking which reports correlate with real vulnerabilities, and building scanner-specific adjustment models. Not something you build once. Institutional knowledge that accumulates over years.
Things Your Fixer Won't Do
Triage is hard. Fixing is harder.
Fix Quality
"Working code" and "good fix" aren't the same thing. A good fix has specific properties:
Safety: 100 — The fix doesn't break existing functionality. Uses PreparedStatement with setString() to safely bind parameters while preserving the query's behavior.
Effectiveness: 100 — The fix actually addresses the vulnerability. Replaces string concatenation with parameterized queries. No partial mitigations.
Cleanliness: 100 — The fix is well-formatted, minimal, and requires no further refinement. No missing imports, no unnecessary refactoring, no style violations.
Your DIY fixer will generate code that compiles. Will it generate code that's correct? That passes code review? That matches your team's conventions? That doesn't introduce subtle regressions?
These quality metrics require training on vast amounts of security fix data, understanding not just what fixes look like but what good fixes look like, and continuously evaluating against real-world merge outcomes.
Merge Rate
Here's what matters: if developers won't merge it, the fix has zero security value.
We track merge rates obsessively. Not because it's a vanity metric, but because it's the only metric that matters. A fix that sits in a PR forever isn't a fix. It's technical debt with a different label. This is why purpose-built remediation systems differ fundamentally from generic AI wrappers — they're designed with merge rate as a first-class concern.
A 76% merge rate — measured across 100,000+ pull requests — exists because:
Getting there requires training on millions of merged PRs, understanding what makes code reviewers accept or reject changes, and building systems that adapt to each codebase's style. It's not "generate a fix." It's "generate a fix this specific team will actually accept."
Workflow Integration
Security fixes that require manual intervention don't scale. Your DIY fixer needs to integrate with:
These aren't features. They're adoption requirements. Without them, your engineering team will route around your fixer because it doesn't fit how they work.
Things Your Platform Won't Do
You've built triage. You've built fixes. Now you need a platform that ties them together. This is where complexity compounds.
Policy Adherence
Every organization has context that scanners don't understand:
### Legacy Code- Mark findings in /src/legacy/v1/ as WONT_FIX: "Legacy system, no new development"- Reduce severity by 2 levels for medstream/legacy/reporting/### Test Code- Findings in /test/, /tests/, /__tests__/ are FALSE_POSITIVE- Hardcoded credentials in test code don't ship### High-Risk Areas- Increase severity by 1 level for /src/api/patient/ (HIPAA)
These aren't edge cases. They're the difference between a tool that generates noise and a tool that generates signal. Your platform needs to interpret natural language instructions and apply them consistently across findings.
This requires understanding organizational context, building policy engines that handle ambiguity, and maintaining instruction adherence as your codebase evolves. Governance infrastructure, not just code.
Scanner Agility
Today you use Snyk. Next year you might switch to Semgrep. Your SAST vendor gets acquired and the product goes sideways.
Scanner agility isn't a nice-to-have. It's strategic necessity. Your platform needs to ingest findings from CodeQL, Semgrep, Snyk, SonarQube, Fortify, Contrast, GitLab SAST, GitLab SCA, Black Duck, DefectDojo, and whatever comes next.
Building integrations for 10+ scanners is months of work. Maintaining them as scanner APIs change is ongoing overhead. Every integration you skip is a scanner you can't use without rebuilding your pipeline.
Continuous Precision Evaluation
AI systems degrade. Models that worked last quarter produce different results this quarter. New vulnerability patterns emerge that your training data didn't cover.
Maintaining precision requires:
This alone is 2 full-time engineers doing nothing but measuring accuracy, evaluating new models, and tuning parameters. Not building features. Just keeping the system from getting worse.
Places Your Platform Won't Go
Even if you build everything above, you've built a single-domain triage and fix tool. The problem is bigger than one scanner type.
Beyond SAST
Your security program generates findings from:
A SAST-only platform handles maybe 30% of your finding volume. What's your plan for the other 70%? Will you build a separate triage system for each source? A separate fixer for dependency upgrades vs. code changes? This complexity is why organizations need security automation at scale.
Context Enrichment
The best triage decisions require context that doesn't live in code:
Building a system that ingests and reasons over this context is a data integration project that dwarfs the ML work.
Preference Learning
Here's something your platform won't do: learn from your decisions through conversation.
"When there's no reachable endpoints, lower the severity but don't call it a false positive. I want to track these patterns even without quantifiable risk."
"Got it. Should I make this a repository-level preference moving forward?"
That's RLHF: Reinforcement Learning from Human Feedback. The system gets smarter from every decision your team makes. It learns your risk tolerance, your coding conventions, your organizational priorities.
This demands infrastructure for preference capture, systems that apply learned preferences at scale, and ML pipelines that improve over time. Not a feature. A different category of system.
The Maintenance Burden
What happens after you ship v1?
Benchmark Management
How do you know your system is accurate? You need benchmarks:
We get input on our benchmarks from F1000 companies across banking, tech, medical devices, and software. That diversity is what makes the benchmarks representative of real-world code.
You'll need to build this from scratch, and maintain it as languages evolve, frameworks change, and new vulnerability patterns emerge.
Quality Assurance Resources
Two FTEs. Full time. Doing nothing but:
Not building features. Not shipping product. Just keeping the system working.
LLM Normalization
LLMs are non-deterministic. Run the same prompt twice, get different outputs.
Developers expect consistent behavior. Executives expect reproducible results. Your platform needs to normalize non-deterministic AI into deterministic-feeling output.
This requires sophisticated engineering: output validation, retry logic, confidence scoring, and fallback handling. Not "call the API." Build a reliability layer that makes an unreliable system feel reliable.
The Zombie Tool Problem
Caleb Sima wrote about this pattern in "The Era of the Zombie Tool." His observation is worth quoting directly:
"Operations is a marriage. When you 'buy,' you are outsourcing the roadmap, the bug fixes, and the 3 AM panic attacks. When you 'build,' you are marrying that code forever."
The zombie lifecycle:
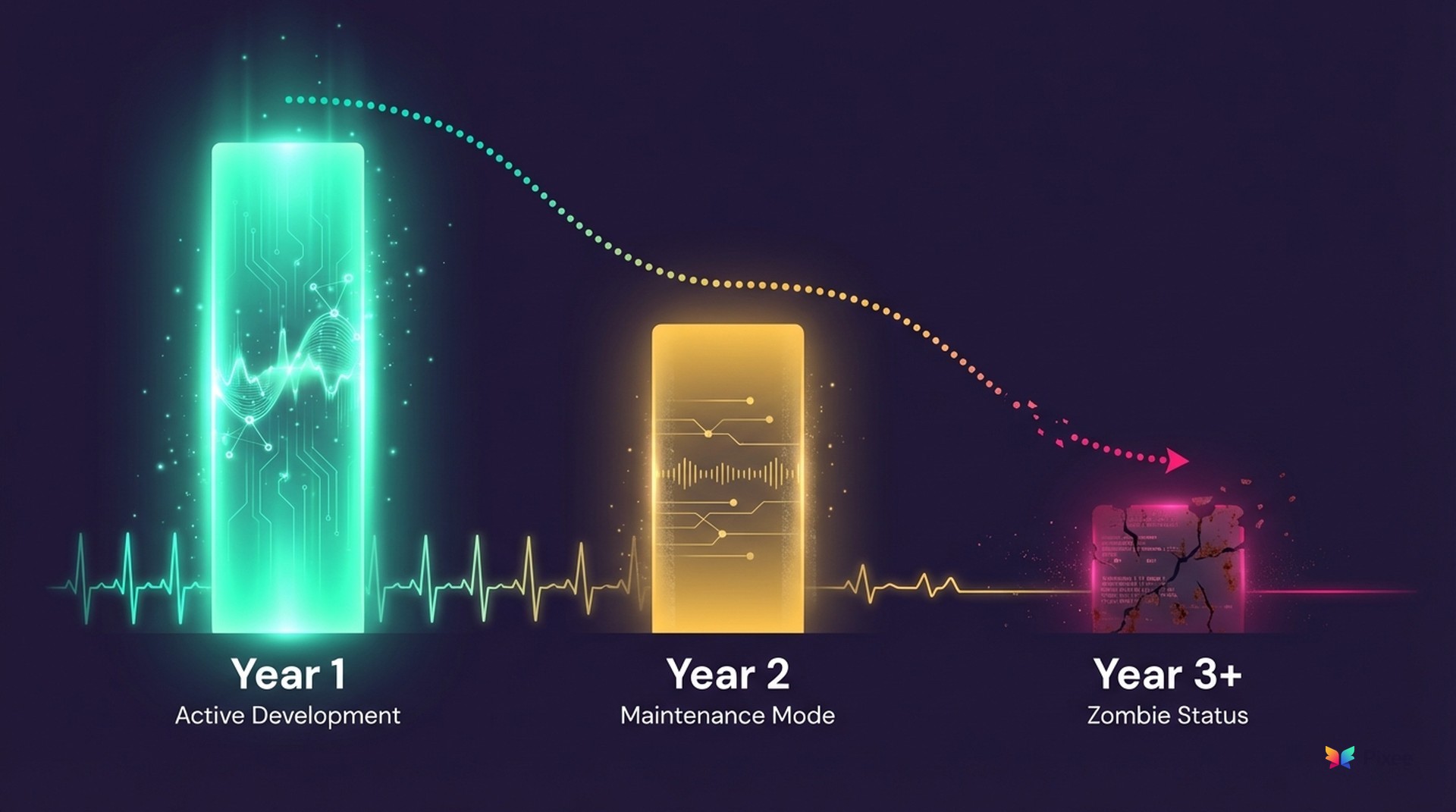
Year 1: Full attention. Active development. The team that built it is invested and improving it weekly.
Year 2: Priorities shift. Maintenance mode. Bug fixes only. New features stall.
Year 3+: Zombie status. It runs. Nobody improves it. Technical debt accumulates. The original builders have moved on.
Sima identifies another insidious pattern: career-driven development bias. Building custom tools offers visibility and promotion opportunities. Engineers reject vendor solutions not because the vendor is worse, but because "we built this" looks better on a performance review than "we evaluated and selected this."
The hidden operational costs of "free" internal tools aren't in the spreadsheet. The opportunity cost of having top engineers maintain internal infrastructure instead of addressing unique business risks. The knowledge walking out the door when that engineer takes a new job.
Ask yourself honestly: after year one, will your team still be investing in improving your DIY resolution platform? Or will they be on to the next initiative?
The Math
Let's make this concrete.
DIY Triage Alone
InvestmentCostEngineering team4 FTEs @ $120K minimumPOC/MVP~$500KUsable product$1M+TimelineDurationSAST-only MVP1 yearProduction-ready2+ years
That's just triage. Not fixes. Not multi-scanner support. Not SCA exploitability analysis. Not context enrichment. Not preference learning.
Hidden Costs
Lowered quality expectations. You'll ship at 80% and call it good enough. That's the nature of internal tooling with competing priorities.
Ongoing maintenance. Who owns this when your lead engineer leaves? When the team that built it gets reassigned? McKinsey found organizations spend roughly 30% of their IT budgets just managing existing technical debt.
Opportunity cost. Every engineer building security tooling is an engineer not building your product.
The 80% Question
Even if you hit 80% accuracy (and that's ambitious), is 80% good enough for security?
That's 1 in 5 findings misclassified. In a backlog of 10,000 findings, that's 2,000 wrong decisions. Some are false positives that waste developer time. Some are false negatives: real vulnerabilities your system said were safe.
What's the cost when a real vulnerability slips through because your triage missed it?
The Alternative
I'm obviously biased. I'm the CTO of a company that builds resolution platforms.
But here's the alternative framing: what if you could deploy something production-ready next month? What if there was a team doing nothing but this — measuring accuracy, expanding scanner support, learning from every deployment — so your team doesn't have to?
What if your engineers could go back to building the things that make your product unique, instead of rebuilding infrastructure that already exists?
Dharmesh Shah, HubSpot's founder, made a similar argument about build vs. buy: the compounding value of dedicated teams doing nothing but this, every day, is difficult to replicate internally.
Some teams do build successfully. Spring Financial built homegrown automated remediation because they're heavily investing in AI across all development operations — with a dedicated platform team. Skyscanner runs a 6-person AppSec team supporting 800 developers and built a mature in-house solution using OpenAI. They're the exception: organizations with dedicated platform teams, multi-year AI investment budgets, and engineering leadership willing to commit 4+ FTEs indefinitely. If that's you, more power to you. But most organizations don't have that luxury — and most shouldn't try to pretend they do.
The build vs. buy decision is yours. I want you to make it with a clear picture of what "build" actually means.
Arshan Dabirsiaghi is Co-Founder and CTO of Pixee. He previously co-founded Contrast Security (valued at $1.3B) and has spent two decades working on application security.
Explore the Full Guide
This post is part of our automated remediation hub resource center. Explore the full guide for frameworks, benchmarks, and implementation playbooks.
Related Analysis
• the case for just fixing vulnerabilities — Fix-first approach to security