How to Reduce False Positives by 80%: A Triage Automation Framework


Seventy-eight percent of security alerts go completely uninvestigated. Not deprioritized. Not triaged and deferred. Just ignored.
That number, from the Nagomi CISO Pressure Index 2025, points to a structural failure, not a prioritization gap. AppSec teams spend 50–80% of their time manually triaging scanner findings rather than remediating real vulnerabilities — and most of that triage effort is wasted on noise.
Better scanners won't fix this. False positive reduction in appsec depends on what happens between detection and action. The industry has poured billions into finding vulnerabilities. The bottleneck was never detection — it's deciding which findings actually matter.
A systematic triage automation framework can reduce false positives by 80% or more and reclaim the majority of your team's capacity for actual security work.
Why Scanners Generate So Many False Positives
The root cause is scanner methodology as opposed to scanner quality.
CVSS scores vulnerabilities in isolation — without understanding your application's deployment model, authentication layers, or compensating controls. The result: 88% of "Critical" CVE ratings are not actually critical in context. A SQL injection finding in a parameterized query. An XSS flag in an API that only returns JSON. A critical dependency vulnerability in a library function your code never calls.
This isn't an edge case. According to the Black Duck Global DevSecOps Report 2025, 71% of organizations report that 21–60% of their security test results are noise: duplicates, conflicting findings, and false positives. The average enterprise runs 5.3 security tools, each with its own false positive profile, severity schema, and alert semantics. When one scanner says "Critical," another says "Medium," and a third says "Not Applicable," a human has to arbitrate. That bottleneck halts velocity.
The damage compounds. Years of false positives train developers to ignore all security alerts — a phenomenon one engineering leader at a large Asia-Pacific financial services firm described bluntly: "When the well is already poisoned, it's very hard to test developers' minds anymore." The cost goes beyond wasted hours — it's institutional trust destruction. Once developers learn to dismiss alert fatigue, even correctly triaged real issues get rejected.
And the problem is accelerating. A recent analysis from DevOps.com found that even as AI and observability tools have reduced raw alert volume, teams are now dealing with decision fatigue — the cognitive load of evaluating which automated assessments to trust. We've moved the bottleneck, not eliminated it.
The Three Categories of "False" Findings
Most teams treat false positives as a single category: the scanner was wrong. In practice, false findings fall into three categories, and conflating them is why most reduction efforts plateau at 30–40%. We covered these in depth in our SAST false positive framework — here's what matters for automation.
Category 1: True False Positives
The scanner fires, but the vulnerability doesn't actually exist. The code pattern matches a known weakness, but the application's logic, input validation, or execution path makes exploitation impossible.
Example: Your SAST tool flags a path traversal vulnerability in a file upload handler. But the handler normalizes all paths through a sanitization library before processing, and the input is validated against an allowlist of file extensions. The vulnerability pattern exists in the code — the exploitable condition does not.
Solving this requires code-level reachability analysis: does a viable attack path actually exist, given the application's defenses?
Category 2: Accepted Risk ("Won't Fix")
The vulnerability is real, but business context makes it acceptable risk. Pure technical analysis misses this category entirely.
Example: A deserialization vulnerability exists in an internal batch processing service. The service only accepts input from a message queue that requires mutual TLS authentication, runs in an isolated network segment, and processes data from a single trusted upstream system. The vulnerability is real — the exposure is negligible.
No scanner addresses this category. It requires organizational context — risk appetite, compensating controls, business logic — not just code analysis.
Category 3: Risk Re-Scoring
The vulnerability exists and could theoretically be exploited, but the actual risk is dramatically lower than the CVSS rating suggests. The scanner says "Critical 9.8" — reality says "Medium 4.2."
Example: A logging library has a CVSS 9.8 remote code execution CVE. But your application runs in a containerized environment with no outbound network access, the vulnerable JNDI lookup feature is disabled by default in your version, and the attack requires crafted input to a log message that your application never exposes to external users. The CVSS score reflects theoretical maximum impact — your actual exploitability is closer to a 3.
This demands deployment and infrastructure analysis that extends beyond the codebase itself.
A security leader at a Fortune 500 financial services institution described it without prompting: "50, 60 to 70 to 80% of findings are false positives OR not important OR don't need to be fixed. The triage effort is entirely manual and requires expertise."
That three-part framing — false positives, not important, don't need fixing — maps directly to these categories. It also explains why reachability-only tools cap out at 30–40% noise reduction: they address only Category 1. Full exploitability analysis across all three categories gets you to 80–85%.
Real-world distributions confirm this. One global financial services company found their SCA findings broke down to roughly 40% true false positives, 30–40% addressable by automation across all three categories, and only 10–20% requiring genuine human expert review.
The Triage Automation Framework: Three Tiers
The categories define what to automate. A tiered framework defines how. The exact distribution varies by organization and scanner mix, but enterprise deployments consistently cluster around this pattern:
Tier 1: Structured Analysis — The Known-Knowns (~60% of Findings)
Pre-configured analyzers handle the vulnerability types your team has seen hundreds of times. SQL injection in parameterized queries. XSS in JSON-only endpoints. Dependency vulnerabilities in functions that are never called.
These are sub-second decisions with 95%+ accuracy for well-understood patterns. Every security engineer recognizes them instantly — and still manually triages them today. Many common vulnerability types across SAST, SCA, and secret scanning can be classified automatically before a human ever sees them.
Your team already knows these patterns are automatable. The question is why they're still processing them by hand.
Tier 2: Agentic Investigation — The Complex Cases (~25% of Findings)
Some findings resist static rules. The vulnerability might be real depending on how the application handles authentication, what network controls exist upstream, or whether a WAF rule already mitigates the attack vector.
Agentic investigation handles these cases dynamically — searching the codebase for security controls, analyzing authentication boundaries, and checking deployment context. Rather than pre-defining every possible scenario, investigation agents reason about each finding's specific context.
Consider the difference from ASPM prioritization: an ASPM tool might tell you this finding is your #3 priority. Agentic investigation determines whether finding #3 is actually a fire, or just a fire alarm test.
Tier 3: Adaptive Analysis — The Unknown-Unknowns (~15% of Findings)
New scanner rules, novel vulnerability types, and custom SAST configurations create findings that no pre-built analyzer covers. Adaptive analysis generates triage logic on-the-fly — analyzing the rule definition, examining how the pattern manifests in your specific codebase, and producing a reusable analyzer for future occurrences.
This tier continuously expands Tier 1's coverage. Every novel finding that gets analyzed becomes a pattern that can be handled automatically next time. The system gets better with every codebase it sees.
The Compounding Effect
The real value emerges over time. Every triage decision and its reasoning gets captured. Developer rejection patterns, suppression evidence, and fix acceptance data accumulate into institutional knowledge. A CISO at a major enterprise software company put it directly: "The pieces they're most compelled about is the triage as much, if not more, than the fixing."
General-purpose AI can evaluate a finding in isolation. What it can't do is learn that your team always accepts risk on internal-only admin endpoints, or that your deployment model makes certain attack vectors irrelevant — organizational context that takes months to accumulate and compounds with every decision.
No system handles every finding correctly from day one. When the automation encounters ambiguous findings — a vulnerability that might be exploitable depending on runtime configuration, or a dependency whose usage pattern is unclear — it flags them for human review with documented reasoning rather than making a silent determination. Those human decisions feed back into the system, expanding coverage over time.
A 14-Engineer Team, Five Scanners, Month Three
Consider a team of 14 security engineers supporting 500 developers — a 1:35 ratio that's typical for enterprise AppSec. As one member of that team described it: "We can't do technical reviews of everyone."
Before the framework: 100+ new findings per day across five scanning tools. Manual triage in JIRA. 252-day mean time to remediation. Engineers spending 80% of their time deciding what matters, 20% on actual security work. Findings that should be triaged "generally get ignored" because there simply aren't enough hours.
After the framework (month 3+): Same team, same scanners. Tier 1 auto-classifies the majority of findings as false positives or accepted risk in seconds — with evidence. Tier 2 investigates complex cases with documented reasoning that security engineers can verify. Human experts handle only the findings that genuinely require judgment.
The first few weeks require tuning — reviewing automated determinations, correcting edge cases, building the organizational context the system needs. By month two, the triage-to-oversight ratio starts shifting measurably.
The metric that matters: time reclaimed for actual security engineering, not "alerts reduced." Teams that have gone through this transition report moving from spending the majority of their time on triage to spending the majority on high-value security activity — though the timeline depends on codebase complexity and scanner diversity.
Once triage is automated, the bottleneck shifts: "What do we do with all these validated real findings?" That's where AI-validated security fixes close the loop — a 76% merge rate on automated remediation, measured across 100,000+ pull requests at 50+ companies. Developers review these fixes and accept them as matching their code conventions, not generic patches.
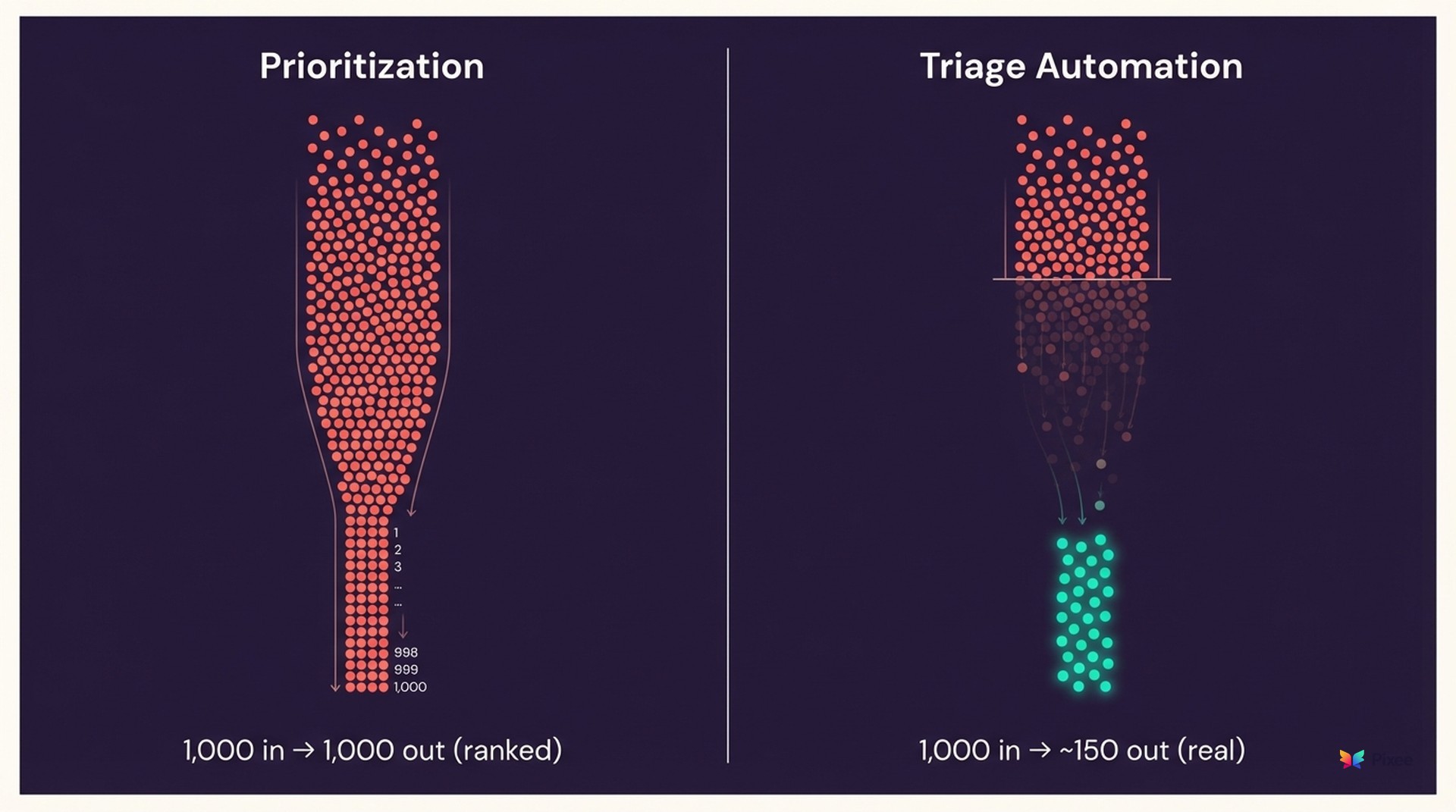
Why Prioritization Isn't Triage
If you're thinking "we already have this" — you probably have prioritization, not triage automation. The distinction matters.
ASPM tools create prioritized lists. Useful, but consider the math: 100 prioritized findings x 3 triage decisions per finding x 2–4 hours per decision = 600–1,200 hours of expert work. You've made the list shorter. You haven't eliminated the work of evaluating each item on it.
Prioritization ranks your problems. Triage automation determines whether they're problems at all.
The data backs this up: 58% of breached organizations had the tools to detect the breach (Nagomi 2025). Detection was solved. Vulnerability backlog reduction requires triage quality, not more detection or better ranking.
A recent Security Boulevard analysis makes the point starkly: SOCs receive thousands of alerts per day and can't investigate 67–78% of them. Adding prioritization to an unmanageable volume gives you a prioritized unmanageable volume. Automated triage — which actually makes determinations about findings rather than ranking them — is the structural fix.
Getting Started
Three steps to begin reducing false positives systematically:
1. Audit your current false positive rate. Most teams don't actually know it. Ask: what percentage of scanner findings did your team act on last quarter? If the answer is below 30%, your triage burden is consuming the majority of your security capacity.
2. Categorize your triage burden. Which of the three categories — true false positives, accepted risk, or risk re-scoring — consumes the most time? This determines where automation delivers the fastest ROI.
3. Automate the known-knowns first. Tier 1 patterns handle 60% of volume with sub-second accuracy. This is the lowest-risk, highest-impact starting point — and it immediately frees capacity for the findings that actually need human judgment.
The 252-day MTTR, the 100K+ vulnerability backlog, the uninvestigated alert volume — you can't hire your way out of these. They require structural solutions. Triage automation is that structure.
Explore the Full Guide
This post is part of our our triage automation hub resource center. Explore the full guide for frameworks, benchmarks, and implementation playbooks.
Related Analysis
• triage automation playbook — Step-by-step triage automation implementation
• after triage, purpose-built AI fixes close the loop — Cross-cluster: from triage to remediation