Why AI Code Fixes Fail Without Context


You have seen this happen. An AI coding assistant generates a security fix. In the demo, it was flawless. In your repository, it broke the build. Or it compiled fine and quietly deleted the feature it was meant to protect. Or it was correct, and no one merged it, because it looked nothing like code your team would write.
The reflex is to blame the model. It is the wrong target. The model that wrote that broken patch is, in most cases, the same class of model that writes correct patches every day somewhere else. What changed was not the intelligence doing the writing. What changed was the context it was given to write against.
An AI writing a security fix is only as good as the slice of your codebase it can see. Give it the vulnerable line and nothing else, and it will confidently patch a symptom while the real flaw sits two files upstream. Give it code without the type definitions and imports that surround it, and it will reference functions that do not exist. The bottleneck in automated remediation is almost never the language model. It is the context chain feeding it.
This piece is about why that happens, and about what "enough context" actually means when the output is a security fix that has to compile, hold up under review, and not break anything.
The four ways context fails
When an AI-generated fix goes wrong, it almost always traces back to one of four context failures. They are worth naming precisely, because each one has a different cause and a different remedy.
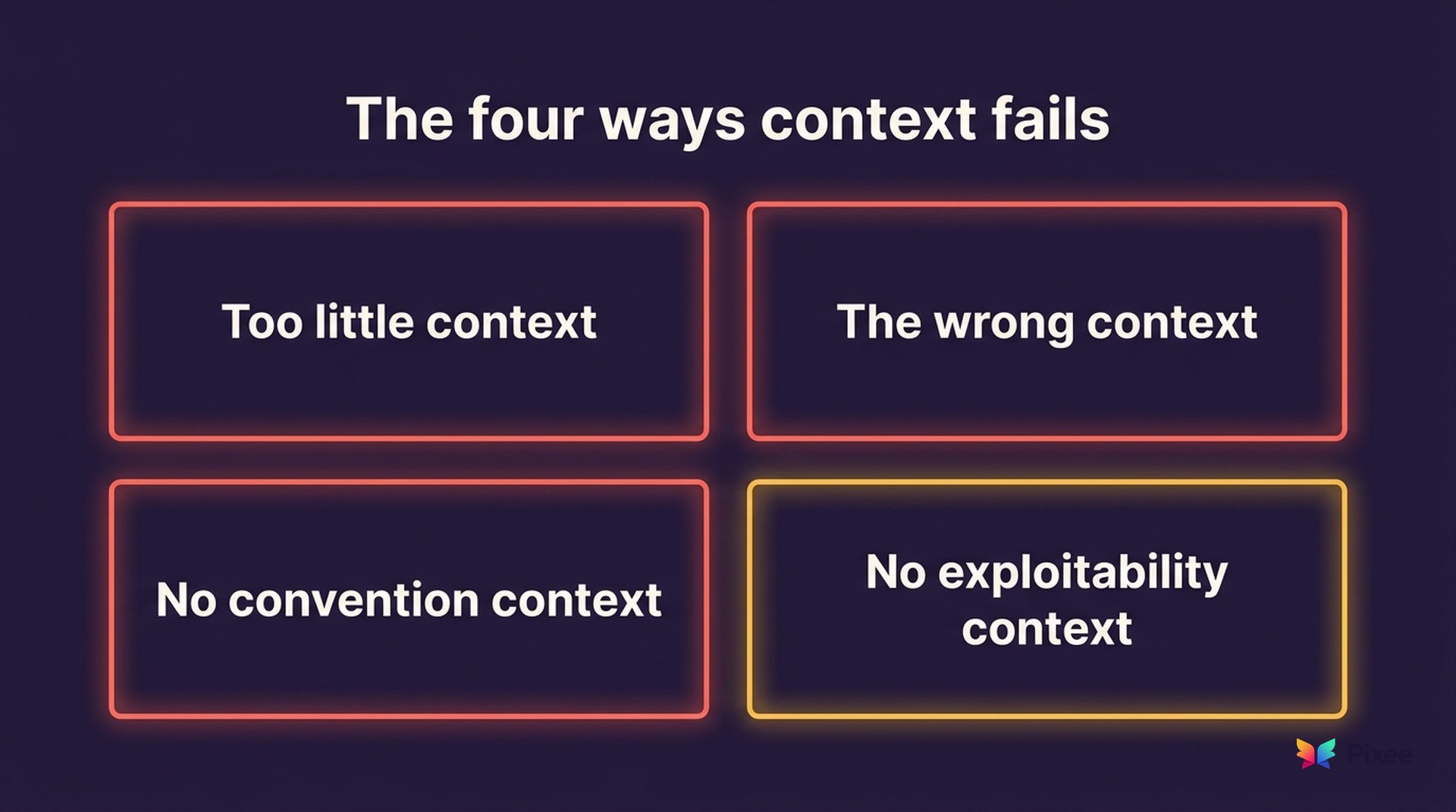
1. Too little context
The model sees the flagged line but not the dataflow that produced it. A SQL injection finding points at the line where a query executes. But the untrusted input entered three functions earlier, got passed through a helper, and was concatenated into the query string somewhere in between. A model that only sees the execution site patches the execution site. The tainted value still flows in from upstream. The scanner goes quiet, the vulnerability does not.
This is the most common failure and the most dangerous, because it produces fixes that look complete and are not.
2. The wrong context
The model has code, but not the code that makes the patch valid. Missing type definitions, missing imports, an unfamiliar module boundary. The fix it writes references a method signature that does not match, calls a helper that lives in a different namespace, or assumes a library version you are not running. The result does not compile. This is the category that produces the "it worked in the demo, it broke in my repo" experience, and it is entirely a function of what surrounded the code the model was shown.
3. No convention context
The fix is correct and it compiles. It still never merges. It uses a logging pattern your team abandoned two years ago, or a validation approach that contradicts your internal standards, or a code style that screams "a machine wrote this." Reviewers reject it on sight, or worse, it sits in the pull request queue until it goes stale. A fix that does not match how your codebase is actually written is, for practical purposes, not a fix. It is a suggestion nobody took.
4. No exploitability context
This is the failure that happens before a fix is ever written, and it is the one most tools ignore. The tool "remediates" a finding that was never exploitable in the first place. A false positive. The vulnerable function is unreachable, or the input is already sanitized upstream, or the code path only runs in a test harness. Now a developer is reviewing a pull request that solves a problem that did not exist. Do that a few dozen times and you have taught your engineers to ignore the tool entirely.
Notice that the first three failures are about generating a good fix, and the fourth is about deciding whether to act at all. They are two halves of the same problem. The context that tells you a finding is genuinely exploitable is the same context that tells the model how to fix it correctly. Triage and remediation are not separate disciplines that happen to share a vendor. They draw on the same understanding of your code.
The evidence that context is the lever
If context were a minor variable, supplying more of it would produce marginal gains. The data suggests it is closer to a switch.
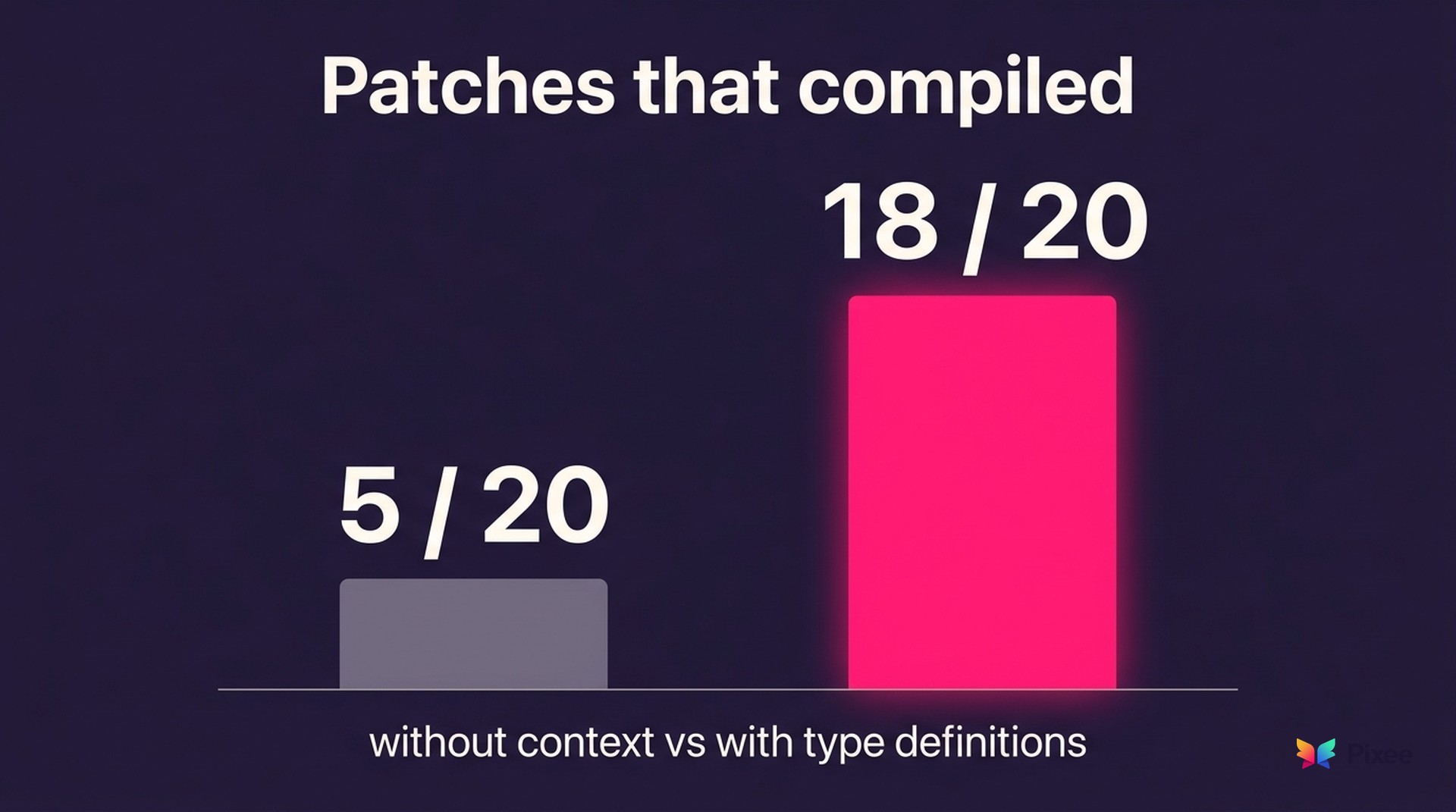
A team competing in DARPA's AI Cyber Challenge measured this directly. Running their patching agent twenty times on a single vulnerability, only 5 of 20 attempts produced code that compiled. When they added one missing piece of context, the type definitions the patch depended on, 18 of 20 compiled (Team Atlanta, 2025). The model did not get smarter between the two runs. It got the context that turns a plausible guess into a working one. One case is not a benchmark, but the direction is the point: the gating factor was context, not capability.
The downstream stakes show up in the broader numbers on AI-written code. A 2025 Veracode analysis that ran more than 100 language models through curated coding tasks found that 45% of the generated samples introduced a vulnerability from the OWASP Top 10 (Veracode, 2025). A separate review of 470 real-world pull requests found AI-written code carried roughly 2.74 times the cross-site-scripting risk of human-written code (CodeRabbit, 2025).
And developers know it. In a survey of more than 1,100 developers, 96% said they do not fully trust that AI-generated code is correct, while only 48% said they always review it before committing it (Sonar, 2026). That gap between "produced" and "trusted" is exactly the gap context closes. A fix you can trust is a fix that arrived with enough evidence to prove it is right.
For scale context, the backdrop these tools operate against is well documented. A majority of organizations report vulnerability backlogs in the six figures, and the time it takes to remediate even half of discovered flaws stretches past 250 days. Automation is the only way through a backlog that size. But automation that ships uncontextualized fixes does not shrink the backlog. It relocates the work from fixing to reviewing.
What "enough context" actually means
Here is the shift in how to think about this. Stop evaluating AI fix tools on the model. Evaluate them on the context chain.
Context chain (defined): the engineered pipeline that decides what an AI model is shown before it writes a fix, and that validates what the model produces afterward. The model is one component inside it. The chain is what determines whether the output is correct.
The four failures above map directly onto what a serious context chain has to do. It has to follow the dataflow so the model sees the whole vulnerability, not just its endpoint. It has to assemble the surrounding code, types, and dependencies so the patch compiles. It has to respect the conventions of the codebase it is editing so the fix is mergeable. And it has to establish exploitability first, so effort is spent only where it matters.
That bundle of requirements has a name worth adopting.
Remediation context (defined): the combination of code context (the full dataflow and surrounding dependencies), convention context (how this specific codebase is written), and exploitability context (whether the finding is real and reachable) that together determine whether an automated fix is correct, mergeable, and worth making at all.
A tool that supplies remediation context produces fixes developers merge. A tool that supplies the model a snippet and a prompt produces the experience at the top of this article.
What to look for in a context chain
This is where it is worth getting concrete, because "give the model more context" is easy to say and hard to do well. Too little context yields wrong fixes. Too much context yields confused models and runaway cost. The engineering is in the calibration. So when you evaluate any AI remediation tool, these are the parts of the chain worth interrogating. The examples below are how Pixee implements each one.
It classifies the strength of the evidence first. Before deciding how much code to gather or whether to act, Pixee assesses the quality of the dataflow behind each finding, distinguishing strong multi-file dataflow from a weak single-location signal. That classification decides both how much context the model needs and whether the finding is worth fixing at all. This is the triage half and the remediation half working from the same signal.
It follows the dataflow across files. Rather than handing the model the flagged line, the same context gatherer traces taint propagation across the codebase, marks the vulnerable region inline, and adapts whole-file versus snippet based on file size. The goal is the calibration point: enough to make the fix correct, not so much that the model loses the thread. Critically, this gatherer is shared between triage and remediation, which is why the exploitability decision and the fix generation stay consistent with each other.
It plans multi-file fixes with specialized agents. When a fix spans more than one file, the work is decomposed: one agent identifies which dependencies need to move, one gathers the source files that require edits, one locates the exact line in the dependency manifest. A vulnerable crypto library does not just get a one-line bump. The plan covers the version change and the source refactors it forces.
It evaluates every fix before a human sees it. This is the step that separates "plausible patch" from "merged fix." Every generated fix, whether it came from a deterministic rule or a language model, passes through a separate evaluator that scores it on three axes: Safety (does it avoid breaking changes), Effectiveness (does it actually resolve the vulnerability), and Cleanliness (is it code a reviewer would accept). Fixes below the bar are sent back for revision with structured feedback, up to several attempts. Fixes that still fail are suppressed, not shipped, with an explanation. So a developer is not the first line of defense against a bad AI fix.
It uses deterministic fixes where the pattern is known. For well-understood vulnerability classes, Pixee applies one of 120+ prebuilt, language-specific codemods with no model in the loop at all. The same input produces the same fix every time. Language models are reserved for the long tail of context-heavy cases, where they pull from that same shared context gatherer plus a curated, per-rule knowledge base.
It spends compute only where the fix earns it. Context discipline is also cost discipline, and this is the part most teams underestimate. The same calibration that keeps the model from drowning in irrelevant code keeps the token bill down. Deterministic codemods resolve common patterns with zero model calls. The context gatherer trims to the relevant region instead of shipping whole repositories. A cache of prior analysis means the second time Pixee encounters a given CVE or rule, it does not pay to reason about it again, which drives a 90%-plus cost reduction on repeated analysis. Right-sized model tiers handle trivial fixes without frontier-model pricing. A chain that sends too much context to too large a model on every finding is not just less accurate. It is the line item that makes automated remediation too expensive to run at backlog scale.
The outcome of that chain is the metric that matters: a 76% merge rate, meaning developers accept and merge more than three of every four fix pull requests Pixee opens, against an industry baseline under 10% for AI-generated code. On the triage side, the same context-first approach is what lets Pixee cut false positives by up to 95% for well-structured findings, so the fixes that do get written are the ones worth writing.
And because the chain spends model budget only where a fix earns it, the economics move the right way as the backlog grows: cost per resolved finding falls instead of compounding. That is the difference between a pilot that demos well on ten repositories and a program that survives ten thousand. Accuracy, cost, and ROI come from the same root cause. Context is not a feature bolted onto either prong. It is the substrate both run on.
None of this is a black box. The merge rate is not a vibe. It is the output of mechanism you can inspect: context gathering you can trace, an evaluation pass with an explicit rubric, and a context graph whose contents are your own code and your own decisions. When a fix merges, you can see why. When one is suppressed, you get the reason. Trust in an automated fix comes from being able to audit how it was made, not from being told to believe the number.
Context that compounds
Then there is what happens over time. A naive fix tool starts every finding from zero. A real context chain accumulates. Each new scanner rule Pixee encounters becomes a reusable analyzer. Each CVE it researches is cached so it is never investigated from scratch again. Each fix it ships adds to a library the next fix draws on. The system gets faster and cheaper the longer it runs against your code.
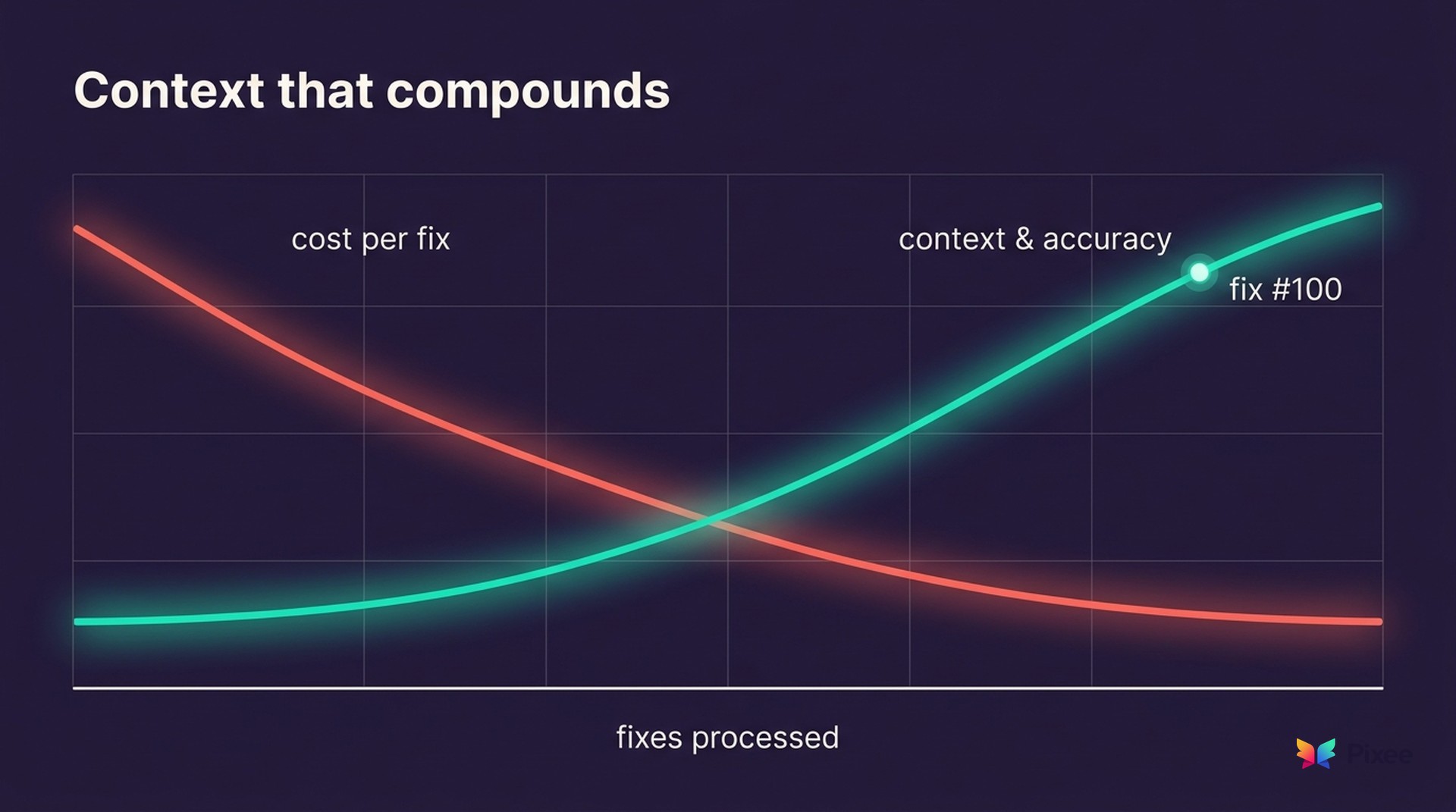
It also gets sharper, because the context graph learns your codebase. Pixee builds and maintains a model of your conventions, your approved patterns, your deployment topology, and your history of past fixes and decisions, then feeds that model back into every new triage call and every new fix.
And it is not a model you have to take on faith. The conventions you encode once in a PIXEE.md policy file are applied to every fix after. The analyzer Pixee generates the first time it meets one of your custom scanner rules is cached and reused on every later finding. The disposition it records on one vulnerability informs how it reasons about the next. The hundredth fix in your repository is shaped by the ninety-nine before it, and you can point at the artifacts that shaped it. Standards your team has already established do not have to be re-taught.
And it runs in both directions. The same understanding that grounds a correct fix after a vulnerability is found is what lets the platform reason about a weakness before the code is written. The reactive prong and the proactive prong share one context graph, so every fix shipped reactively teaches the proactive side what to watch for, and every risk caught early sharpens the exploitability calls downstream. One understanding of your codebase, compounding across both prevention and remediation. This is the part a tool built on a single scanner or a stateless model cannot copy: context that is yours, that accumulates, and that makes every next decision better than the last.
The takeaway
When an AI fix fails, the postmortem usually ends at "the model got it wrong." It rarely was. The model wrote a reasonable answer to the question it was actually asked, and the question was missing most of the context that would have made the answer correct.
So change the question you ask of any AI remediation tool. Not "how good is the model," but "how good is the context chain." Specifically:
- Does it follow the dataflow, or just read the flagged line?
- Does it gather the dependencies that make a patch compile?
- Does it know your conventions?
- Does it establish exploitability before it spends your developers' attention?
- Does it check its own work before a human has to?
- Does it spend compute only where a fix earns it, or send everything to a frontier model and hand you the bill?
- Does it learn your codebase and get sharper with every fix, or start from zero each time?
Those questions predict merge rates better than any benchmark of the underlying model. Context is the lever. Everything else is the model doing its best with what it was handed.
If you want the longer version of how a context chain holds up across both triage and remediation at enterprise scale, how Pixee runs VulnOps walks through the full pipeline. Or see how the chain is built end to end on the platform overview.