Every Security Vendor Has AI Now. None of Them Know Your Code.


Mythos dropped exploit discovery costs 99%. Defense costs didn't move. Context engineering is what closes the gap.
Anthropic's Mythos model discovered thousands of zero-day vulnerabilities across every major operating system and browser. It found a 27-year-old OpenBSD TCP SACK flaw that survived decades of manual code review. It generated 181 working Firefox exploits where Anthropic's previous model succeeded twice.
Within 48 hours, the Cloud Security Alliance assembled 60+ CISOs from Google, Netflix, Cloudflare, and Wells Fargo to produce a risk register and action plan. The Federal Reserve convened emergency bank CEO briefings. Anthropic launched Project Glasswing, a $100M defensive coalition. Every security vendor started pivoting messaging to "Mythos-ready" and "agentic AppSec."
The response was fast. The framing was familiar. And it missed the point.
AI-driven vulnerability discovery is no longer the bottleneck. Within 18 months, every major lab will have Mythos-class capability. "We use AI" is not a differentiator. It is table stakes. The question that determines which organizations survive the Mythos era is not whether they can find vulnerabilities faster. It is whether they can fix them.
What the Playbooks Miss
The CSA's MythosReady paper is the most significant coordinated CISO response to an AI capability announcement in the industry's history. It introduces a 13-item risk register, an 11-item priority action list, and the concept of VulnOps as a permanent organizational function. Anthropic published seven defensive recommendations. Both are substantive.
Both share the same gap. Neither addresses what happens when the tools they recommend generate findings at 71-88% false positive rates. Neither discusses whether AI-generated fixes actually get merged.
Your engineers already spend 6.1 hours per week triaging security alerts, and 72% of that time is wasted on noise. That adds up to roughly $20,000 per developer per year in lost productivity. At a 1,000-person engineering organization, $15 million annually goes to investigating findings that turn out to be nothing.
Meanwhile, 65% of organizations say false positives forced their teams into risky behavior: dismissing findings, delaying fixes, bypassing checks entirely. AI-generated code compounds the problem. 69% of organizations found vulnerabilities introduced by AI-generated code. CodeRabbit's analysis shows AI-written code produces 1.7x more issues, with incidents per pull request up 23.5% year over year. The result: critical findings quadrupled while security teams stayed the same size.
Anton Chuvakin calls it the "Patch Sound Barrier." Every organization has a maximum remediation velocity. AI-driven discovery has permanently exceeded it. More scanning at those false positive rates does not shrink the backlog. It grows the triage queue.
Every playbook correctly identifies the destination. None of them engineer the route for a specific enterprise with specific code. That route has a name: context engineering. And the economics explain why it matters now.
The Cost Asymmetry: Offense Got Cheap. Defense Didn't.
The economics of vulnerability discovery collapsed in two years.
In 2023, discovering a critical zero-day required weeks or months of work by elite security researchers. The cost: six figures. By 2024, Daniel Kang at UIUC demonstrated automated exploit generation at $8.80 per working exploit, with GPT-4 exploiting 87% of one-day vulnerabilities. In April 2026, Anthropic's red team reported Mythos discovering roughly 1,000 zero-days at a total cost under $20,000, with individual exploit chains completing for under $2,000.
A 99% reduction in two years. Discovery is effectively free at scale.
Defense costs did not move. It still costs roughly $790 to touch a single finding: $250 to understand it, $300 to communicate it internally, $240 to verify the fix. Full remediation of a high-severity vulnerability runs $4,000 to $7,000 and takes a median of 252 days. The average organization now faces 865,398 security alerts, up 52% year over year. After prioritization, 795 critical findings remain, up from 202. Nearly four times more than last year.
Less than 1% of Mythos-discovered vulnerabilities have been fully patched.
An attacker can discover and chain a working exploit for under $2,000 in a day. A defender spends $4,000 to $7,000 and 252 days to fix one finding — if they get to it at all. The asymmetry is the structural crisis of the Mythos era. No amount of additional scanning closes it.
Context closes it.
Context-aware triage suppresses 88% of unexploitable findings before a human sees them. Context-aware supply chain analysis eliminates another layer. According to Endor Labs and Semgrep's analysis of 50,000+ repositories, reachability analysis reduces actionable alerts by 70-90%. Context-aware remediation generates fixes that developers actually merge at a 76% rate instead of the sub-20% rate typical of generic AI.
The math is stark. Offense costs dropped 99% in two years. Defense costs dropped 0% without context. With context, each layer compounds reductions across triage, visibility, and remediation. This is not a feature comparison. It is the difference between an organization that keeps pace and one that falls behind permanently.

What Context Engineering Actually Means: Three Layers
"Context matters" is easy to say and hard to operationalize. Here is what context-aware remediation looks like at each layer of the supply chain, using SCA (software composition analysis) as the proof architecture. The supply chain is where the gap between legacy tooling and context-aware approaches is most visible.
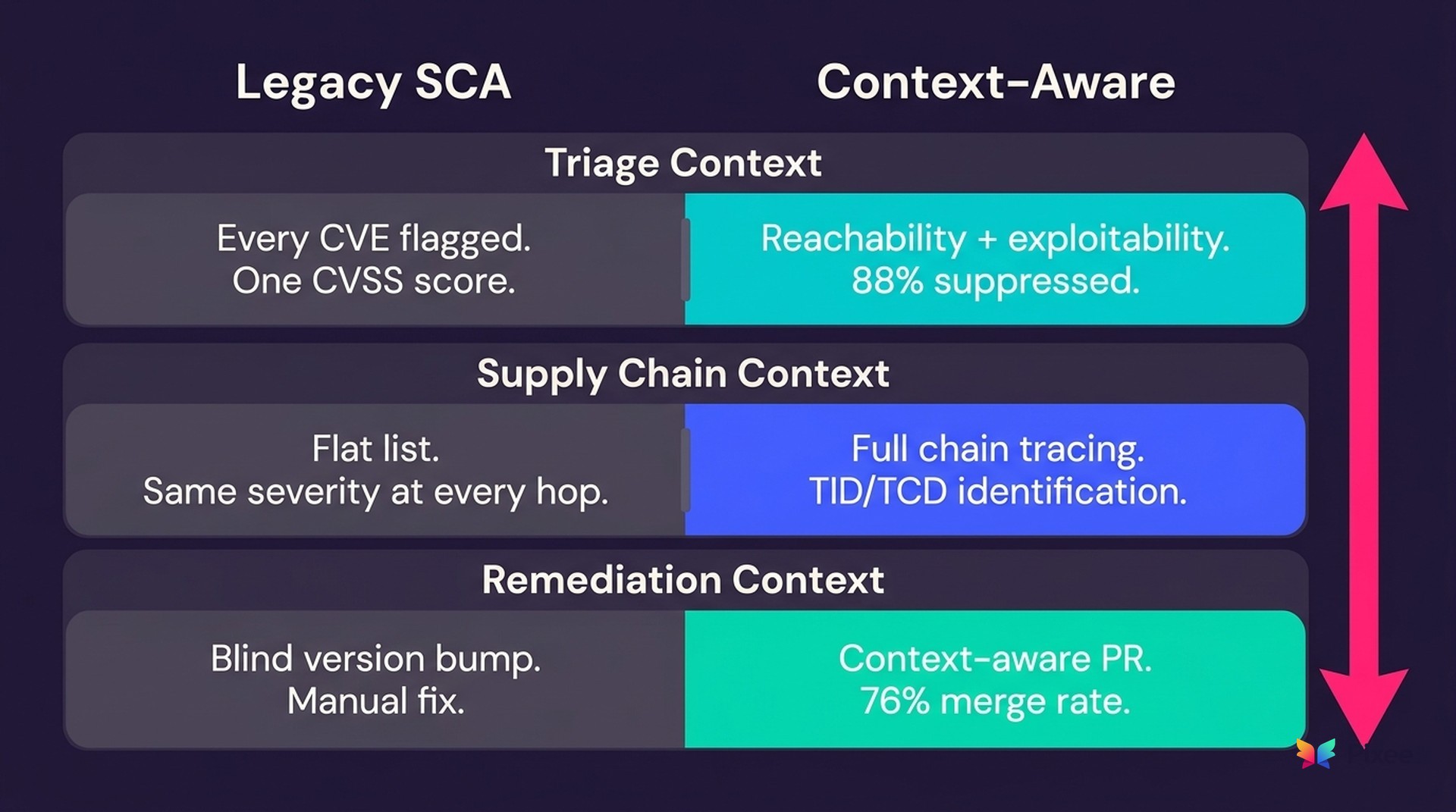
Layer 1: Triage Context — Same CVE, Different Risk
Legacy SCA tools flag every CVE in every dependency. One CVSS score from the vendor. No code analysis. No proof of exploitability. Your team investigates each one manually, and 88% of flagged CVEs turn out to be unexploitable in the application where they were found.
Context-aware triage changes the equation. Call graph and data flow analysis proves whether the vulnerable function is actually reachable from your application before alerting. Risk scores adjust based on reachability, data flow, your deployment environment, and historical outcomes. Every verdict includes an exploitability classification with evidence, which means review time collapses from hours to minutes.
Consider a critical Log4Shell-class CVE in a transitive dependency. At a fintech processing payment data, the vulnerable logging path accepts untrusted input from a public API and writes directly to an unfiltered log sink. The exploit chain is three hops from the internet. At an internal analytics team, the same library exists in a batch reporting service that only processes pre-validated internal data behind two network segments. Same CVE. Same CVSS 9.8.
Legacy SCA sends both teams identical critical alerts. Context-aware triage sends the fintech team a critical finding with an auto-generated fix and sends the analytics team a low-priority note to address during the next maintenance window. One team stops everything. The other plans it for next sprint. Both responses are correct because the tool understood the code, not just the CVE.
Layer 2: Supply Chain Context — The Hidden Chain
Legacy SCA shows you a flat list of package names. Transitive CVEs carry the same severity as direct dependencies. There is no visibility into how the vulnerable library is actually reached through your dependency chain.
A vulnerability four layers deep through an unused code path is categorically different from a direct exposure. Without chain context, your SCA tool treats them identically.
Context-aware supply chain analysis traces the full dependency chain from your application root through every intermediate library to the vulnerable package. It identifies TIDs (Taint Introducing Dependencies) and TCDs (Taint Consuming Dependencies), which tells you exactly which direct dependency introduced the risk and which one consumes it. Risk calibration adjusts per layer and accounts for blast radius when multiple taint-initiating dependencies converge on the same vulnerability.
Without TID identification, you do not know which direct dependency to upgrade. With it, you know exactly where in the manifest hierarchy the patch needs to go. And when the parent library has not yet released a patch, you can create an override fix that replaces the taint-introducing dependency with a safer version. Without hierarchical context, that fix is impossible to generate.
This is where context dilution becomes visible at architectural scale. On Unsupervised Learning, Pixee CTO Arshan Dabirsiaghi described the dynamic directly: "Every new surface you cover dilutes the context your system has about each one. Context dilution is exactly where automated fixes start breaking." In the supply chain, that dilution is literal. Each hop in the dependency chain reduces visibility unless you trace the full path.
Layer 3: Remediation Context — Fix Without Fear
Legacy SCA remediation is a blind version bump. Pick the latest version and hope it does not break your build. No breaking change analysis. You upgrade and find out. The recommendation arrives as a separate finding, and the developer implements it manually. The friction between finding and fix means findings age in backlogs.
Context-aware remediation replaces guesswork with evidence at every step. Version selection accounts for framework compatibility, runtime constraints, and historical upgrade outcomes in similar codebases. Changelog review combined with multi-path dependency analysis and historical PR patterns flags potentially breaking upgrades before they ship. The result arrives as a pull request with rationale, a confidence score, and code that matches your codebase conventions.
The automation model is progressive, not binary. Human-in-the-loop review comes first. Auto-application happens only when confidence is high and validation passes. This matters because developer trust is not a feature you can ship. It is a pattern you earn.
As Pixee CTO Arshan Dabirsiaghi puts it: "If developers won't merge it, the security value is zero." The 76% merge rate is not an abstract benchmark. It is the result of context at every layer: knowing your conventions, your test suite expectations, your dependency constraints, and your team's historical preferences. Remove any of those context inputs and the merge rate drops to the industry standard: below 20%.
Why Context Compounds
These three layers share a property that generic AI does not: they get better with organizational use.
A context graph captures every triage decision, every merge and rejection pattern, every suppression rationale, and every fix acceptance. By month six, the system reflects your team's coding patterns, upgrade preferences, and risk tolerance. By year one, it aligns with your team's documented preferences because it has organizational memory that no individual engineer carries alone.
Foundation Capital describes this architectural shift broadly: the last generation of enterprise software captured what exists (customers, employees, operations). The next generation captures why decisions were made. Not records. Decision traces. In security, the same principle applies.
Your scanners record what vulnerabilities exist. Your ASPM records what priorities were assigned. Nothing records why something was triaged out, why a fix was rejected, or why a precedent applies. That decision trace currently lives in people's heads. It walks out the door when they leave.
An architecture that captures those decision traces and makes them queryable, replayable, and auditable changes the economics. When a developer rejects a fix, the system records the rejection pattern and adapts future fixes to match what your team actually trusts. When a finding is suppressed, the reasoning is preserved so the same finding does not consume triage cycles again next quarter.
Arshan describes the philosophy as the "march of nines." Get each capability to 99.9% accuracy before expanding to the next. Breadth dilutes context. Depth compounds it.
This matters because context-aware remediation requires an initial learning period. On day one, the system operates on reachability and exploitability analysis alone. The compounding effect requires organizational adoption — merge and reject signals that only accumulate with use. For teams that need immediate triage relief, the first layer (exploitability suppression) delivers results within hours. The deeper compounding takes months. That honesty about the curve is part of the architecture.
The compounding effect is the structural answer to the Mythos era. When discovery accelerates, you need remediation that accelerates with it. Generic AI plateaus. Same model, same merge rate, same noise regardless of how long you use it. Context-aware systems compound. More organizational use produces better triage, better fixes, higher merge rates — the kind of architecture where remediation velocity can eventually exceed discovery velocity.
In early enterprise deployments, teams have seen over 90% of findings triaged automatically with 60-70% of backlogs addressed through combined triage and automated remediation.
Why AI Alone Is Not Enough
Chuvakin's Patch Sound Barrier is not a metaphor. It is an engineering constraint. Every organization has a maximum remediation velocity, and AI-driven discovery has permanently exceeded it. The industry's response is correct in direction and incomplete in architecture. "Use AI to defend" is necessary. It is not sufficient. Every vendor will have AI.
What separates organizations that survive the Mythos era from those that accumulate permanent vulnerability debt is whether their defensive automation understands their specific environment — their code, their conventions, their dependencies, their risk tolerance, their team's historical behavior — well enough to produce results their team will act on.
Context engineering is the architectural difference between remediation that compounds and remediation that plateaus. Between defense costs that collapse and defense costs that stay fixed while offense costs approach zero.
You cannot outwork machine-speed threats. You also cannot out-AI them. You out-context them.
If you want to see what context-aware triage and remediation look like on your codebase, a proof of concept takes under two hours.
Related reading from Pixee: