Case-Based Reasoning for Triage: An Episodic Memory Layer for Pixee's Classification


Triage That Remembers What You Taught It
We just released a deeper memory layer for AutoTriage.
Pixee users can now weigh in on a verdict — a thumbs up on a true positive, a thumbs down on a false positive, with a note about the missing context. Maybe a finding is senseless because that input source is actually protected by an upstream validator, or because the SHA-1 in the code is risk-exempt because that's just how a partner expects in the signed payloads we send to them.
This feature (and more we'll talk about soon!) are another proof point in how Pixee can turn these low-signal findings into business outcomes.
A Real World Example
Here's a real finding from a CodeQL scan on Apache Roller:
int page = 0;
if(request.getParameter("page") != null) {
try {
page = Integer.parseInt(request.getParameter("page"));
} catch (NumberFormatException notIgnored) {
response.sendError(HttpServletResponse.SC_BAD_REQUEST, "Malformed URL");
return;
}
}
Our analysis always attempts to determine if what was asserted was true, but also tries to determine if in context, this is a real issue. In this analysis, we said, yes, the user could make this a negative number, and potentially cause downstream damage with an unexpected value.
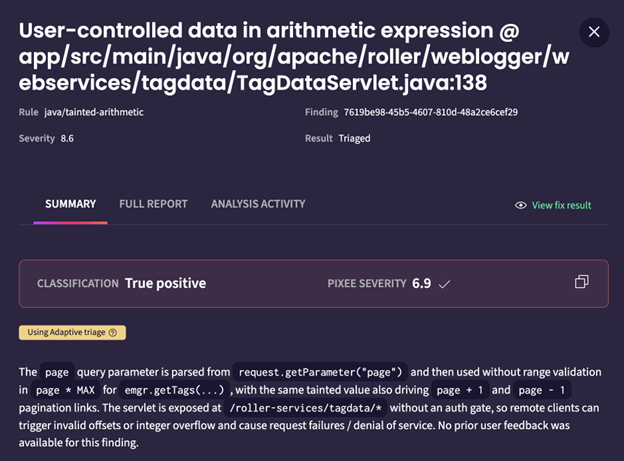
However, I wanted the system to be more strict about this type of finding in the future. I told it to be more stringent about how to review these cases:

Now, after another scan, our triage reviewed past feedback on similar findings, and changed its classification behavior:

How Does It Work?
It is a case-based reasoning system, with some domain-specific twists to help improve performance. Over time, this episodic memory will go through a journey, combine into higher level types of indexable and searchable memory, and feed into the organization's knowledge graph.
These features, in combination with our existing speed and coverage, mean the system starts to feel more and more native to the organization.
Why Not Fine-Tuning, RLFT, RLHF, etc?
Engineers now have many tools to create learning systems from users. Why did we settle on CBR? Many tools come into vogue and we pride ourselves on our ability to sort out great tools for our use cases inside our enterprise customers, as opposed to whatever's running hot on LinkedIn and HN.
Here's the 10,000 foot summary:
Built for the Enterprise
Of course, to an enterprise, the best part? All this happens in your compute, with whatever model you want, with all the controls to make compliance and AI governance happy. Some vendors haven't figured out yet that customers want to own their data in the AI era.
Over the next few weeks, we'll start rolling this feature into more and more of our system's touchpoints, allowing us to proactively, automatically, and efficiently scale episodic memory to all our operations.
We'll also be making all the memory transparent, auditable, and controllable, so the blast radius is understood, only the right people can influence memory, and more.
Join us in the movement to go from systems of detection to systems of decision.