VulnOps: The Operational Playbook for Mythos-Ready Security Programs


Vulnerability Operations (VulnOps) is the operating layer of a security program that ingests findings from every detection source, dispositions them under a single exploitability and severity model, generates validated remediations against the codebase, and writes an auditable record of every machine-judged step. The program then runs as fast as findings arrive, without losing the ability to show its work. Pixee runs the Resolution side of VulnOps today: up to 95% of findings dispositioned and dropped at the triage gate, and the PRs that do open merge as-is at a 76% rate.
Get the full whitepaper (PDF) →
TL;DR
In early May 2026 the Cloud Security Alliance, SANS Institute, [un]prompted, and the OWASP GenAI Security Project published The AI Vulnerability Storm: Building a Mythos-Ready Security Program. The paper is the industry's coordinated response to what effective cybersecurity programs will look like given a permanent structural acceleration in offensive AI capability.
The signatories include Google, Sysdig, Cloudflare, Sophos, Rivian, NFL, Atlassian, GitLab, Salesloft, TransUnion, Justworks, lululemon, FDIC, and dozens more.
Sixty CISOs do not co-author papers casually.
The paper is an industry wake-up call, arguing that defense has to be re-framed for a world of machine-speed exploitation. To some extent that has already been true. The window between vulnerability disclosure and confirmed exploitation has compressed from 2.3 years (in 2018) to under 24 hours (in 2026). But the pressure is only compounding as Anthropic's Mythos and successor frontier models continue to ship over the coming weeks.
To respond to this moment, the paper argues that we need to implement eleven priority actions (PAs):
• PA 1 — Point Agents at Your Code and Pipelines (Detection)
• PA 2 — Require AI Agent Adoption (Foundation)
• PA 3 — Defend Your Agents (Foundation)
• PA 4 — Establish Innovation Governance (Foundation)
• PA 5 — Prepare for Continuous Patching (Resolution)
• PA 6 — Update Risk Models and Reporting (Resolution)
• PA 7 — Inventory and Reduce Attack Surface (Detection)
• PA 8 — Harden Your Environment (Foundation)
• PA 9 — Build a Deception Capability (Foundation)
• PA 10 — Build an Automated Response Capability (Resolution)
• PA 11 — Stand Up VulnOps (Resolution)
The paper groups these PAs into governance, risk control, and operational enabler categories. We like to think of them as mapping to detecting vulnerabilities and attack surfaces, fixing vulnerabilities with a compliance and audit trail, and general foundational work across governance, risk control, and general operational enablement.
That looks like this:

Taken together the recommendations flow into a new category of defense they name Vulnerability Operations, or VulnOps: the operating layer that ingests findings from every detection source, dispositions them under a single exploitability and severity model, generates validated remediations against the codebase, and writes an auditable record of every machine-judged step. The program then runs as fast as findings arrive, without losing the ability to show its work.
To us, a well-functioning VulnOps practice requires taking both a proactive approach to hardening code before it's written and a reactive approach to patching vulnerabilities as soon as they are created and discovered.
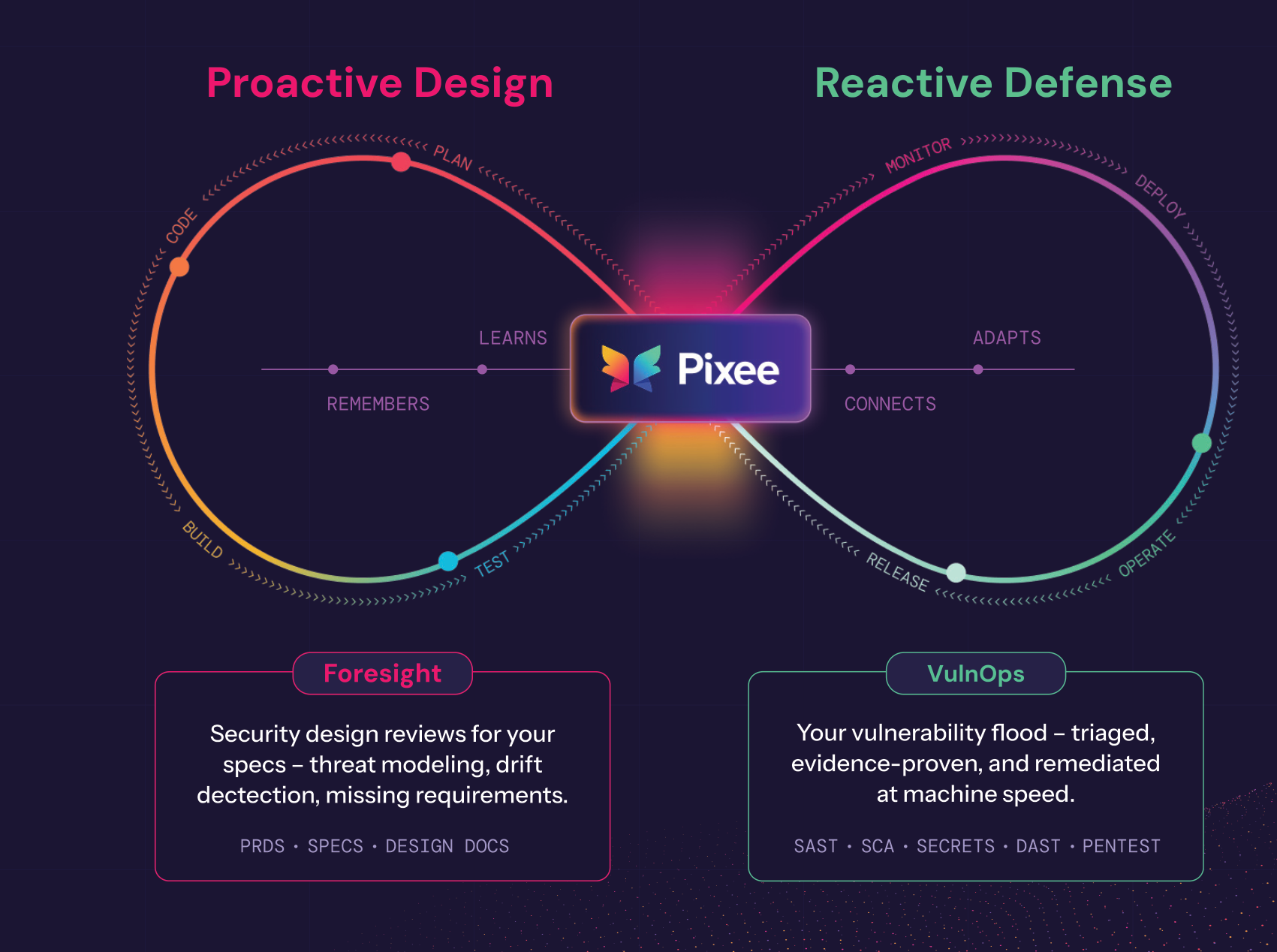
On the reactive, fix side of the house — which is where this paper concentrates — it looks like this:

In the rest of this paper we focus on what it takes to build machine speed defense in the resolution layer of vulnerability operations. This is the space Pixee has been operating for over two years with automated triage and fix agents spanning SAST and SCA handling everything after vulnerability detection. Increasingly it also relates to our Foresight product which focuses on hardening architecture choices at design and PRD stages in order to catch gaps before a single line of code is written. The beauty of this dual approach is that we create a closed loop that enhances the contextual layer that any machine speed defense program must prioritize building (a separate topic we've written about here).
Section 1 — The Mythos Shift: What Changed in 2026
The state of the union: a crisis of find-but-never-fix
Before Mythos, the existing AppSec stack was already failing to keep pace with human-driven offense.
• The Ponemon Institute reports 66% of organizations carry 100,000+ open vulnerabilities.7
• Veracode's longitudinal State of Software Security 2025 reports a 252-day average time to remediate critical flaws.8
• SAST industry baseline false-positive rates run 71–88% per scanner.9
• 81% of teams ship vulnerable code because of capacity, not negligence.
Aside from a weakened security posture, this has a real cost. Aikido reports developers spend 6.1 hours per week on triage at a productivity cost of roughly $20,000 per developer per year.1
This is the find-but-never-fix gap, and it predates the AI shift entirely.
This is the baseline. Now enter Mythos and AI-enabled attack velocity.
Mythos takes this to a whole new level
The window between vulnerability disclosure and confirmed exploitation has compressed from 2.3 years (2018) to 56 days (2024) to under 24 hours (2026). Sergej Epp's Zero Day Clock at Sysdig has the data. It's still moving the wrong direction. For example:
• Anthropic Mythos preview (April 2026) generated 181 working Firefox exploits where Anthropic's prior Opus 4.6 model produced 2 under the same internal lab conditions. The paper reports a 72% exploit success rate on full chains.10
• DARPA AICC finalist systems found 54 vulnerabilities and produced exploits across 54 million lines of code in 4 hours of compute.11
• Anthropic Claude Opus 4.6 found and reported 500+ high-severity OSS vulnerabilities in February 2026. The same evaluation surfaced 12 OpenSSL zero-days, including a CVSS 9.8 dating from 1998 that survived 28 years of human code review.
As the CSA authors state, "The window between discovery and weaponization has collapsed into hours. This represents a permanent acceleration, not a temporary spike." (Paper p.8.) The time collapse is significant. The permanence of that collapse is what necessitates shifts in our approach.
This is not human researchers working faster. Offensive AI now chains exploit primitives that used to take weeks of human work, against vulnerability classes it's been trained to recognize. There's no version of that capability that gets slower.
Where do current approaches breakdown?
On the resolution side of vulnerability operations we see three typical bottlenecks across clients we start working with.
Scanner and Tool Stack Sprawl
Scanner sprawl breaks first. Most enterprise security teams run five or more scanners across SAST, SCA, container, and IaC. Each ships its own UI, severity model, finding metadata, and false-positive rate. At human-speed offense, the noise was painful but somewhat palatable. At machine-speed offense, every minute your team spends triaging a false finding from one scanner is a minute the exploitable finding from another stays open. Cross-scanner triage is not a feature of any single-scanner product. By definition, it cannot be.
Human-speed Fixing
Manual remediation breaks second. Human triage and hand-coded fixes scaled because the input volume was somewhat humane. Throw in more AI-driven exploits and higher exploitable AI generated code in general2 and the backlog gap continues to widen. As the CSA authors bluntly put it: "we cannot outwork machine-speed threats."
Poor Fix Quality with General LLMs
The last breaking point is more nuanced. It is the fact that generic AI-generated fixes get rejected by reviewers at high rates. We all know frontier models will gladly propose patches. But without elaborate context engineering and an understanding of your organization's specific security architecture these fixes usually do not match codebase conventions, often import unfamiliar libraries, or fail existing tests.
As tempting as it is to throw tokens at the problem, that doesn't scale, in terms of either quality or cost (we break down the buy vs. build question at length here).
What "Mythos-Ready" means, defensively
If we can’t outwork machine-speed offense and machine-speed code generation the only option is to build a machine-speed defense program.
"Mythos-Ready" is the operational state of running a security program that produces validated, merge-ready remediation artifacts at the same rate findings arrive. In our mind, this means discovery, triage, fix generation, validation, and PR creation operating as a continuous pipeline rather than a queue.
Concretely, a Mythos-Ready program has four defensive characteristics:
• Cross-scanner unification at ingestion, not at the dashboard. Findings from every scanner enter one normalized queue with one exploitability model, one severity convention, and one disposition tracker. Manual scanner-by-scanner reconciliation does not survive machine-speed input volume.
• Triage discipline as a gate, not as the bottleneck. Exploitability and reachability run automatically and continuously, not as a periodic human review pass. Findings that fail the triage gate never enter the remediation pipeline. Findings that pass are eligible for fix generation.
• Fix generation that produces merges, not patches. Codebase-conforming fixes, validated against existing test suites and conventions, opened as PRs against the right branch. The metric is merge rate, not PR rate.
• Engineering merge-decision authority preserved. VulnOps generates merge-ready candidates and tracks dispositions; engineering reviews and merges. The per-PR triage burden disappears; the merge-decision authority does not. Machine speed does not mean no human-in-the-loop anywhere, it means carefully considered checkpoints.
Scope note. This playbook is not arguing that detection and discovery are obsolete. The paper's PA 1 — pointing agents at your code and pipelines — names specific commercial discovery vendors (Anthropic Claude Code Security, OpenAI Codex Security, Knostic, raptor, Trail of Bits agentic skills) that form a new AI detection layer on top of existing scanners. Those tools are upstream of the operating layer this playbook describes; they feed it findings. Our argument, and what we’ve built at Pixee, is that the primary bottleneck in AppSec is not finding issues, it’s understanding which issues matter and fixing them at speed with quality.
How to know if you have a problem?
Before any vendor evaluation makes sense, three diagnostics tell you whether your current stack is at the breaking point or still ahead of it. None of these require a PO or a procurement cycle.
• Count your scanner severity models. List every scanner producing findings against your stack today — SAST, SCA, container, IaC. For each, write down how that scanner ranks severity and how its top-severity tier compares to the others. If you can't reconcile three or more severity scales into one prioritization ranking on a whiteboard, the manual triage layer is already operating on guesswork. That's the cross-scanner unification gap we’re talking about
• Measure your 100-finding triage throughput. Pick the next 100 findings any scanner produces into your queue. Time how long it takes a triage analyst to disposition all 100 (reachable, exposed, compensated, false positive) to a level you'd defend in an audit. Divide 100 by hours-of-analyst-time. That number is your current triage rate. Compare it to the rate findings arrive: if findings arrive faster than your analysts can disposition them, you're going backwards.
• Audit your vulnerability fixes. Walk your last 90 days of security-driven pull requests by bug class. Which classes merged at >80% without engineering edits — dependency bumps, hardcoded-secret removals, library-version pins? Those are the candidates a written auto-merge policy could move out of the per-PR review queue tomorrow, before any new tooling is in scope. The point is to confirm engineering review queue throughput is the binding constraint, not lack of clean candidates upstream.
These three diagnostics are the prerequisites to evaluating any VulnOps function, whether vendor-built, in-house, or hybrid. If the diagnostics return "we're fine," the rest of this playbook is reading material, not action. If they return what we typically see when we walk a customer through them — irreconcilable severity scales, inverting triage rate, idle auto-merge candidates — the rest of this playbook is the operational map.
Section 1.5 — Can we prevent vulnerabilities in the first place?
Everything above this section is the reactive side: findings arrive, the pipeline triages them, the pipeline fixes the ones that survive, the audit trail records what happened. That is the core work of Pixee’s triage and fix agents.
A reactive program ingests vulnerabilities that already exist in code that already ships. This work is foundational, and machine-speed offense makes it matter more, not less. But a program that only operates after detection is permanently downstream of the rate at which new exposures get authored.
As AI-assisted coding increases code velocity more of the security-relevant decisions need to happen earlier, in places the scanner stack will never see. To us that means shifting even further left than ever into the PRD, in the ticket, in the spec before code is ever written. That's the proactive side of machine speed defense.
Building Proactive defense before code is written
AI is or will write the vast majority of code in your organization. Which means we can actively improve the security posture of that code by engineering the context and security awareness in the design phase. But no security organization has the headcount to deep-review every design across their product functions, which is why most designs get a cursory pass and the gaps get caught (or missed) in production when there are already vulnerabilities. The problem extends past PRD review. Even a good PRD review needs to translate its promises to action, e.g. to tickets, and then to trace the implementation of those promises in the actual code.
Our newest product, Foresight — now live in production — is designed to do just that. It starts with a product requirement document or PRD. The system reads it the way a senior security reviewer would. It seeks to identify the components involved, surface the gaps where the PRD assumes tribal knowledge, and research those gaps across the customer's actual systems (GitHub, Notion, ticketing, internal docs, repo structure). From there it creates a structured set of security promises the PRD makes. Some are explicit ("all exported PII must be encrypted with SHA-256"). Some are implicit ("a new internal service is being created, which under this organization's existing pattern must register with AppSec"). It then ensures those promises make its way into tickets, flagging gaps and proposing additions proactively. In other words, security promises in the design stage serve as an ongoing unit of accountability in the entire SDLC that hardens your code before it's ever written.
Why the proactive side cannot stand alone, and why the reactive side cannot either
A program that runs only Foresight would be incomplete in the same direction a reactive VulnOps-only program is incomplete. Foresight catches what gets designed in; it does not retroactively fix the backlog of code that already shipped. VulnOps catches what scanners surface from code that already shipped; it does not prevent the next batch from being authored. Both modes are necessary because they operate on different inputs at different points in the SDLC, and the same organization has both kinds of risk every day.
The integrating concept is that both feed one Context Graph. The auditable dispositions VulnOps produces and the security promises Foresight produces are different shapes of the same record — structured evidence of a security-relevant decision, with rationale, traced to the artifact (PR, ticket, PRD, finding) that triggered it. When the Graph is shared, the proactive side learns from what slipped through to the reactive side, and the reactive side gets earlier signal on the classes of work the proactive side is catching. The closed loop is an enduring structural advantage for your organization that scales regardless of any other build vs. buy or model considerations you pursue.
What this looks like in practice

The shared record has a name on each side. On the reactive side it is the auditable disposition — the structured record Pixee writes for every triage drop, fix regeneration, fix exit, and PR merge, with rationale. That disposition stream is the substrate underneath the merge-rate methodology, the substrate underneath the false-positive-reduction claim, and the evidence a customer's risk model points to when it needs to show its work (PA 6). Every machine-judged step writes one; nothing exits the pipeline silently. On the proactive side the same-shaped record is a security promise, extracted from a PRD rather than emitted from a triage decision. Both flow into the one Context Graph above.
Core Architecture Principles for Agentic Security Design
Regardless of whether you consider Pixee’s product or are pursuing building your own solutions our 3+ years of building agentic security pipelines involve a lot of hard-won lessons that should be valuable. Here are four of the most important.
Clearly define gates: Clear gates that fail closed. Every stage has a deterministic gate. A finding that fails any gate stops there. The pipeline does not produce PRs that introduce new bugs or violate branch policy, full stop.
Create Accountability via per-finding disposition tracking. Every finding has a logged disposition (merged, closed, deferred, escalated) flowing back to the risk model and the methodology disclosure.
Create constraints to your LLMs. Agentic guardrails on every machine-judged step. Where the pipeline reasons, it reasons under named constraints: triage bounded to reachability, exposure, and compensating controls; fix generation bounded to candidates that pass test-suite, convention, and regression-risk checks before any PR opens.
Prioritize context engineering at every layer. The pipeline never generates a triage decision or a fix from finding metadata alone. Codebase conventions, framework patterns, deployment context, and dependency-chain context are vital inputs at every stage.
Build with cost optimization in mind too. The CSA Mythos paper highlights one additional complexity in the machine-speed era: a cost asymmetry between offense and defense that the per-finding numbers obscure unless you read them carefully.
Offensive AI produces a complete exploit chain for roughly ~$2,000.3 On the defensive side, a single finding-touch — a triage pass, a fix attempt, a regression check — runs roughly ~$790,4 and findings take many touches before they exit the pipeline. Full remediation of a single finding sits in the $4,000–$7,000 band.5 Multiply by the volume of findings a modern enterprise stack produces and the cumulative defensive cost dwarfs the offensive chain.
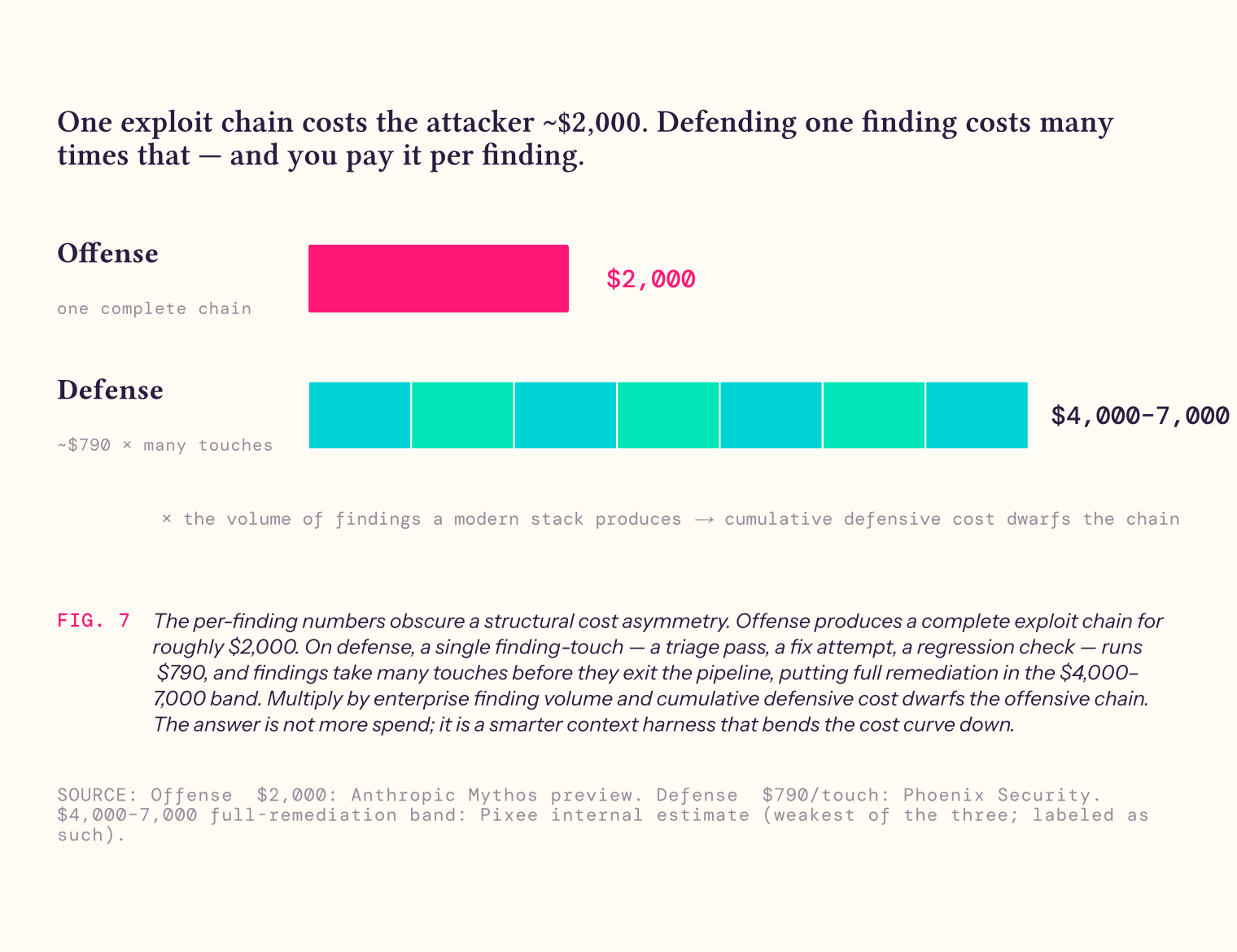
At scale this is akin to launching million dollar interceptor missiles at $20,000 attack drones. The solution isn't more missiles. It's a smarter harness that lets you deploy context strategically to ensure efficient and effective fixes that drop the cost curve dramatically.
These principles are what produces the numbers. Because triage runs as a gate rather than a periodic review pass, up to 95% of findings are dispositioned and dropped before they ever reach an engineer's queue. Because every fix candidate must clear a validation gate (existing tests still pass, codebase conventions are honored, and the change stays scoped to the fix) before a pull request opens, the PRs that do open merge as-is at a 76% rate (per Pixee's published methodology), against an industry baseline of 30–40% for unsupervised AI fixes.6 Triage that drops the noise and remediation that merges are co-equal outcomes of the same disciplined pipeline, not a fix bolted onto a scanner.
The last hard-won lesson is operational, not architectural. Don't roll this out everywhere all at once. Seems obvious but the most common failure mode we see in a rollout is the engineering review queue. Cap PRs per repository at the start, prioritize the highest-exploitability findings, and raise the cap only as the team builds trust in what comes through. Again — more merged fixes is the goal, not more PRs. As the disposition stream accumulates merge-decision data per bug class, the classes that clear review with near-zero edits (dependency bumps, hardcoded-secret removals) can (if desired) graduate to pre-authorized auto-merge under written policy for less important repos.
Next step
Mythos and successor frontier models ship in the coming weeks. Teams who stand this function up before then will spend that window ahead of the curve. Everyone else will spend it catching up.
Get in touch at pixee.ai/vulnops.
Get the full whitepaper
The complete VulnOps: The Mythos-Ready Security Playbook as a designed PDF. Full operating-layer detail, all nine figures, and the proactive and reactive model. No form, no email required.
Sources & references
Anchor paper. Cloud Security Alliance × SANS Institute × [un]prompted × OWASP GenAI Security Project, The AI Vulnerability Storm: Building a Mythos-Ready Security Program, v1.0 (originally 12 April 2026; last revised 1 May 2026; CC BY-NC 4.0). 60+ named CISO co-authors and reviewers. Paper landing.
Pixee operational references. VulnOps landing · Scanner integration matrix · Public PR footprint · Context engineering · Methodology disclosures.
Contact. Surag Patel, CEO, Pixee — surag@pixee.ai. The 30-minute walk-through is bookable at pixee.ai/vulnops.
Footnotes
1. Aikido developer-productivity benchmark — 6.1 hours/week on triage, ~$20,000 per developer per year. ↩
2. CodeRabbit's analysis of 470 real pull requests found AI-generated code produced 2.74× more cross-site scripting (XSS) errors than human-written code. Similar increases appear across improper password handling (1.88×), insecure object reference (1.91×), and insecure deserialization (1.82×). ↩
3. ~$2,000 per offensive exploit chain — Anthropic Mythos preview (claims registry C001/C002), per 08_campaigns/mythos_wave/market_intelligence/2026-04-20_mythos-cost-synthesis.md. ↩
4. ~$790 per defensive finding-touch — Phoenix Security (C006), same synthesis. ↩
5. $4,000–$7,000 full-remediation band — Pixee context-engineering estimate; weakest of the three sources, cited as a Pixee-internal estimate rather than third-party study. ↩
6. 30–40% industry baseline merge rate for unsupervised AI-generated code fixes — Pixee internal benchmarking against off-the-shelf LLM patch-suggestion output (per the methodology disclosure linked above); directional, not a third-party study. ↩
7. Ponemon Institute, organizations carrying 100,000+ open vulnerabilities — referenced in Pixee buyer-pain synthesis (CORE_buyer_pain_points_synthesis.md). ↩
8. Veracode, State of Software Security 2025, longitudinal MTTR for critical flaws. ↩
9. SAST industry baseline false-positive range, 71–88% per scanner — cross-referenced in vendor benchmark literature; see Pixee's false-positive analysis. ↩
10. Anthropic Mythos preview results (181 Firefox exploits vs. Opus 4.6's 2; 72% full-chain success) — Anthropic internal lab evaluation, cited in CSA × SANS × [un]prompted × OWASP GenAI, The AI Vulnerability Storm, v1.0 (2026). ↩
11. DARPA AI Cyber Challenge (AICC) finalist results (54 vulnerabilities + exploits across 54M LOC in 4 hours of compute) — DARPA AICC final results, August 2025, cited in CSA AI Vulnerability Storm, v1.0. ↩