Context Engineering for Security: Why Context, Not the Model, Decides the Fix

Every security vendor has an AI story now. Triage assistants, autofix buttons, agentic this and copilot that. Within eighteen months, frontier models will be close enough in raw capability that "we use AI" tells a buyer almost nothing. The model is becoming the commodity.
What separates security automation that holds up from automation that quietly fails is what that model is allowed to see, and how carefully that information is assembled. The same model, handed the right information about your codebase, makes a correct security decision. Handed a snippet and a CVE number, it guesses. The difference between those two outcomes is context engineering.
This page defines that discipline, shows the evidence that context (not model choice) drives security outcomes, and walks through what context engineering for security looks like across the full software lifecycle, from the design stage to the open pull request.
What context engineering for security actually is
In mainstream AI engineering, the term arrived quickly. In June 2025, Andrej Karpathy endorsed "context engineering" over "prompt engineering," describing it as "the delicate art and science of filling the context window with just the right information for the next step." Anthropic later gave it a working definition, calling context engineering "the set of strategies for curating and maintaining the optimal set of tokens (information) during LLM inference" and "the natural progression of prompt engineering."
Context engineering for security is that discipline applied systematically to assembling, calibrating, and validating the information an AI needs to make correct security decisions across the software development lifecycle. It looks to inject information about Whether a finding is exploitable. Whether a fix is safe. Whether a design introduces a class of risk before a line of code exists. Those are not generic language tasks. They depend on facts about your code, your conventions, your dependencies, and your runtime that no general model carries on its own. It is a specific and unforgiving job because security has such a high bar.
This is also where a common conflation needs clearing up. A "context graph" is a data structure, a way of storing relationships between code, findings, and decisions. It is useful, and several vendors market one. But a data structure is not a discipline. Context engineering is the practice of deciding what to put in that structure, what to retrieve from it, when, and how to prove the result was right. The graph is plumbing. The engineering is the judgment.
The evidence: context beats a smarter model
The instinct is to assume a smarter model solves security AI. The evidence points elsewhere: capability without the right context plateaus, and context lifts the same model dramatically.
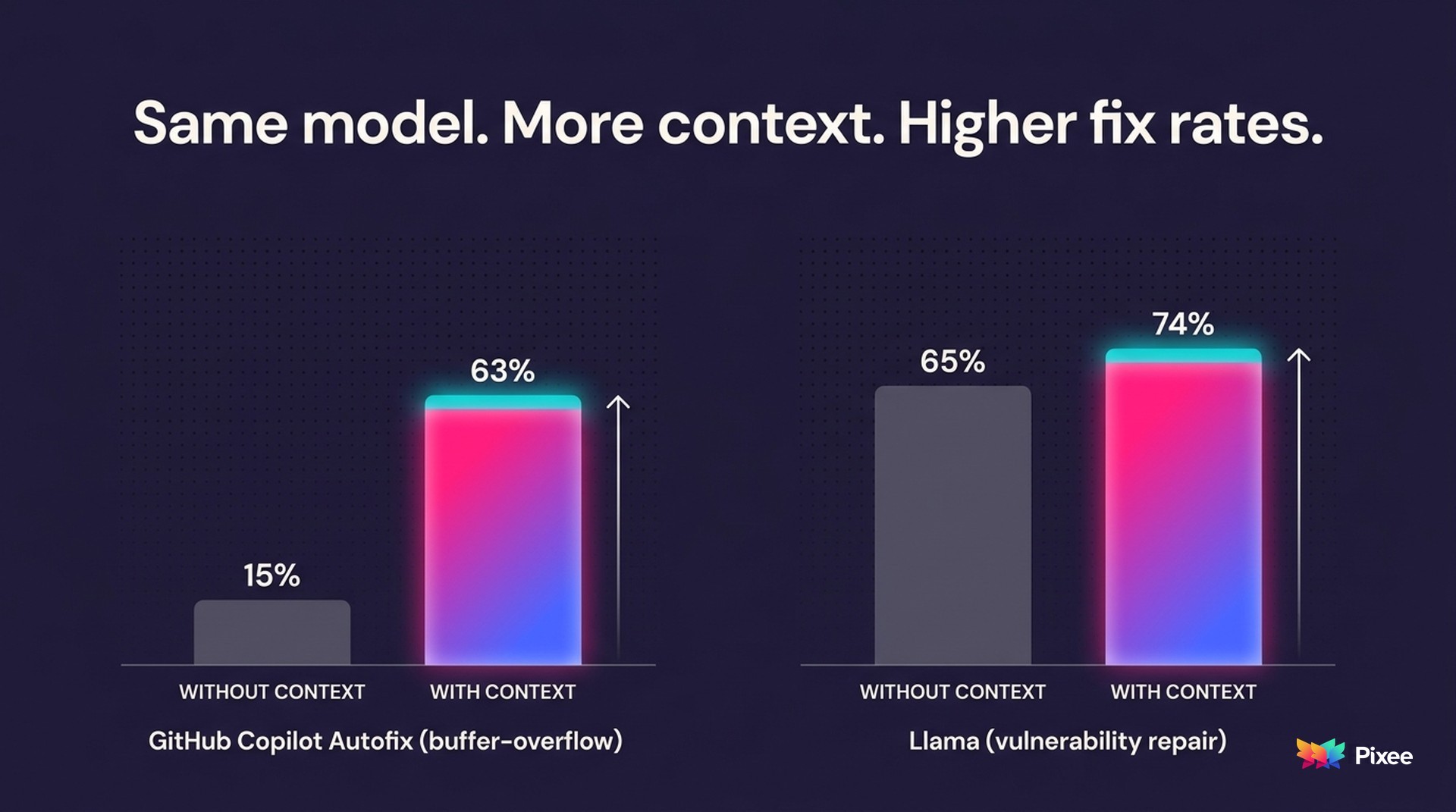
Start with a controlled result. In a 2025 study, researchers measured GitHub Copilot on buffer-overflow vulnerabilities. It detected them at a 76% rate but repaired them at only 15%. After the researchers injected security and code context about each vulnerability, the same model's repair rate rose to 63%, more than four times the improvement. Same model, one variable changed. The scope matters and should not be oversold: this result is specific to buffer-overflow repair, not every vulnerability class. But the direction is unambiguous. Detection is not repair, and context is what closes the gap.
A second, independent result points the same way. In a 2025 program-repair study, injecting repository knowledge (co-occurring files, structural dependencies, recent changes) on top of bug-report context raised Llama 3.3's fix rate from 65% to 74%. The baseline was already strong, so the gain is incremental rather than dramatic, which if anything understates the point: even a well-fed model does better when it understands the surrounding repository.
There is a reason naive "just give the model everything" approaches fail, and it is structural. More tokens do not guarantee better use of them. The "lost in the middle" research from Stanford showed that model performance is highest when relevant information sits at the beginning or end of the input and "significantly degrades" when the model has to use information buried in the middle, even for models built for long contexts. More recent work found that input length alone degrades performance by 13.9% to 85% even when the model can perfectly retrieve the relevant facts. (A widely cited "context rot" benchmark across 18 models reports the same pattern; note that it comes from Chroma, a vendor with a commercial interest in retrieval, so weigh it as a controlled benchmark rather than neutral arbitration.) The takeaway for security is direct: stuffing a giant prompt with every file is not context engineering. Curation is.
That is consistent with what shows up elsewhere in security AI. DARPA's AIxCC work saw a compile rate for AI-generated patches move from 5 of 20 to 18 of 20 once type definitions were supplied. In Veracode's 2025 testing, AI-generated code introduced security flaws in 45% of tests. AI-written code shows more issues per change, not fewer. Developers know it, which is why most distrust AI fixes by default. None of this is solved by a bigger model. It is solved by giving the model the right information and proving the result.
The kinds of context security AI needs
If context is the work, then naming the kinds of context is the map. Security decisions draw on two distinct families of input, and most tools assemble only the first. (This is the positive mirror of the ways context fails, which we cover in depth in why AI code fixes fail without context; here the focus is on what to assemble, not how it breaks.)
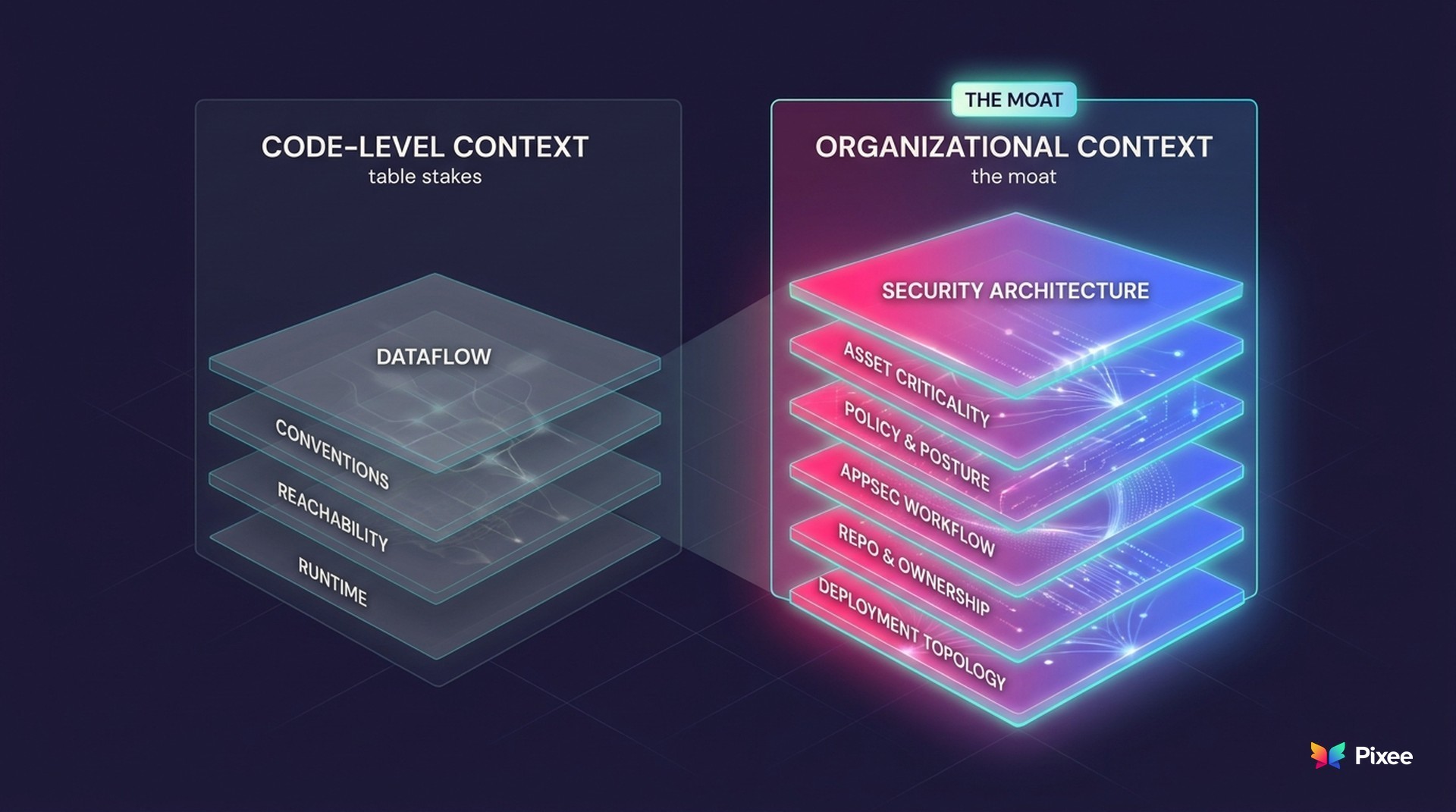
The first family is the code itself, the technical substrate most AI security tools already reach for:
• Code and dataflow context. How data moves from source to sink across files, so the AI reasons about the actual program rather than a snippet.
• Convention context. Your naming, your patterns, your idioms, so a fix reads like your team wrote it and survives review.
• Exploitability and reachability context. Whether a vulnerable function is actually reachable and exploitable in your application, which separates a real fire from a theoretical one.
• Runtime context. How the code behaves and is configured when it runs, which can promote or demote a finding's real risk.
The second family is your security program, the organizational substrate a generic model has no way to know:
• Security architecture and trust boundaries. How the system is designed, where the seams are, and which crossings actually matter.
• Asset criticality and business impact. Which repositories and services are crown-jewel, internet-facing, or regulated, so the same finding gets a different response depending on what it threatens.
• Policy and posture. The rules, approved patterns, and compliance posture your organization has decided to enforce.
• Program workflow. How findings route, who owns what, where the gates and SLAs sit, and when something escalates. The way your AppSec program actually runs is itself context, and a decision that ignores it lands in the wrong queue or the wrong hands.
• Repository and ownership structure. Monorepo or many, CODEOWNERS, service boundaries, so a fix reaches the team that can review it.
• Historical decisions. What your team triaged out before, what fixes were accepted or rejected, and why, so the same question does not consume review cycles every quarter.
• Deployment topology. Where a service sits, what it is exposed to, and what surrounds it.
Most tools specialize in one or two items from the first family. Reachability analysis is a recognized example of exploitability context, and several autofix tools now read the surrounding codebase rather than a lone snippet. That breadth of activity is the signal that "use the code as context" has become table stakes. The discipline is engineering both families together, and the second family is the decisive one, because it is uniquely yours. Your architecture, your criticality map, your policies, your program's workflow, and your accumulated decisions are not facts a model can be pretrained on. They are the context that makes a security decision correct for your enterprise specifically, and they are why context, not the model, is the durable advantage.
Context engineering across the lifecycle
Here is where the discipline becomes a system rather than a feature. Security decisions are needed at two very different moments, and context engineering applies to both.
Going in, at the design stage. Before code exists, the highest-impact security context is the intent: what is being built, what data it touches, what could go wrong by design. Reasoning about a planned change against that intent catches a class of risk that no scanner can find later, because there is nothing to scan yet. This proactive prong reads the design, models the risk, and flags the gap before the code is written, then watches for drift when the shipped change does not match what was promised. In practice that surfaces as a specific, reviewable note while the work is still a design rather than a deployed surface: this proposed endpoint takes untrusted input on a path with no planned authorization check. It is the front half of the lifecycle, and it depends on context about intent and architecture rather than about a specific line of code.
Coming out, in triage and remediation. Once code and findings exist, the job flips. Scanners produce volume, much of it noise. Context-aware triage uses dataflow and reachability to suppress what cannot be exploited, which is where a 70% to 95% reduction in false positives, depending on vulnerability type, comes from: not a smarter classifier, but better information about whether each finding matters in your application. Then context-aware remediation generates a fix grounded in your conventions and dependencies and proves it before proposing it. That grounding is why its proposed fixes reach a 76% merge rate, the share developers actually accept, against the sub-20% typical of context-poor autofix. A fix developers will not merge has zero security value, regardless of how clever the model that wrote it was.
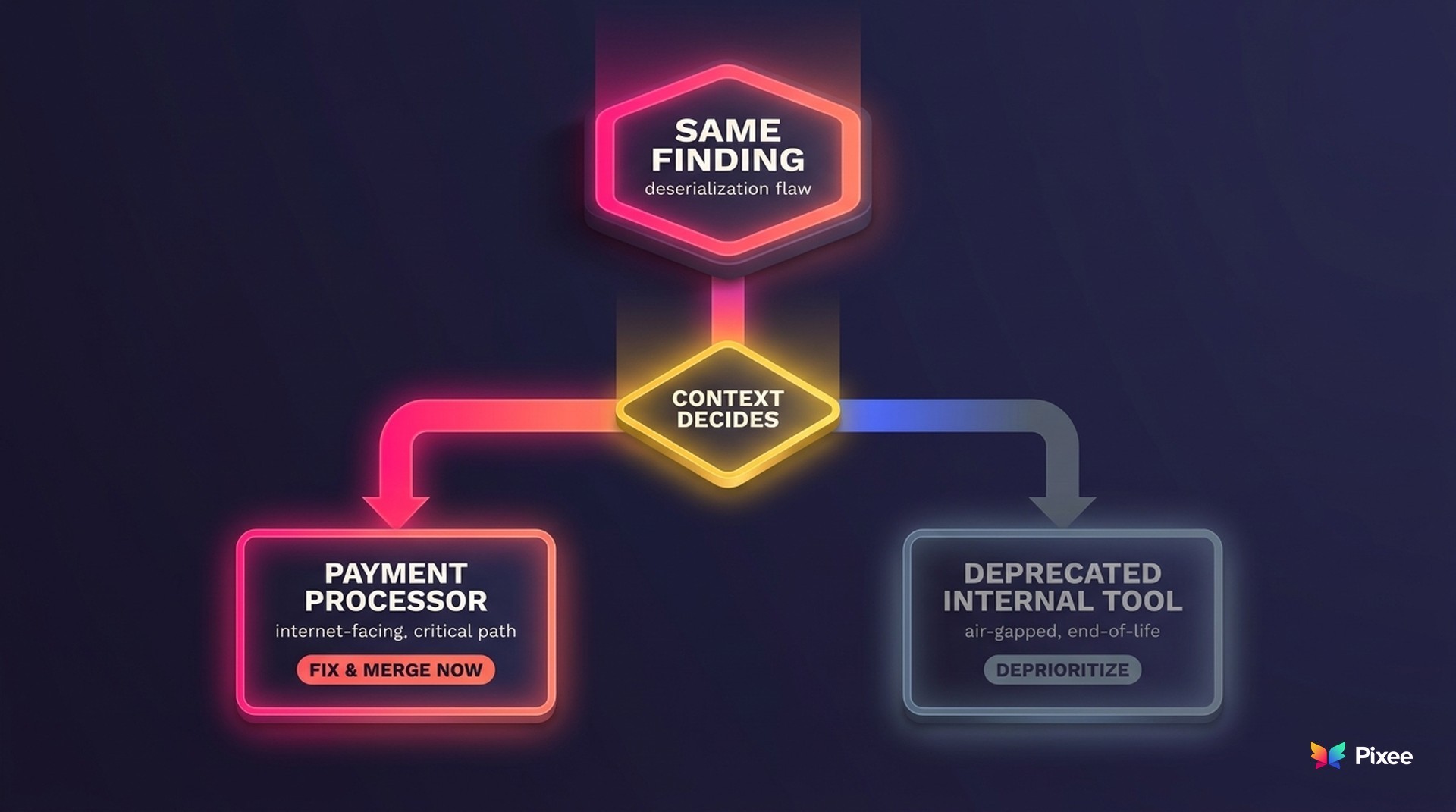
Make it concrete. Picture the same deserialization flaw in two internal services, with identical code-level facts and a reachable vulnerable path in both. Program context is what tells them apart. One service sits in the criticality map as a payment processor in regulatory scope, owned by a team with a seven-day remediation SLA, so the finding becomes a tracked, high-priority fix routed straight to that owner as a pull request that matches their conventions. The other is a deprecated internal reporting tool already scheduled for decommission next quarter, so the same flaw is recorded, linked to the decommission plan, and deferred rather than fixed. No amount of dataflow analysis decides that split. The criticality map, the ownership model, and the program's workflow do.
The reason both prongs belong in one discussion is that they draw on the same accumulating body of context, and much of it is the second family from the section above. The reachability facts that demote a finding, the conventions that shape a fix, the design intent that flagged a risk early, the criticality map that says this service is internet-facing and that one is not, the policy that defines an approved pattern, the program workflow that decides who owns the result, and the dispositions a team recorded last quarter: these are not separate silos. A security decision is only "correct" relative to that program context. Route a real finding past the wrong owner, or propose a fix that violates an approved pattern, and the decision fails no matter how sound the code analysis was. Engineered well, the same context that prevents a class of bug at design time also sharpens triage and remediation when something slips through, and it lands the result inside the workflow your team already runs. That shared foundation is what turns a collection of features into a discipline, and it is the part a single-moment tool cannot replicate.
The harness: where context engineering operates
It helps to name the structure that all of this runs inside. The model writes or analyzes code. The harness around it decides what the model sees, judges whether its output is safe, and remembers why each decision was made. If the model is the commodity, the harness is the product.
Concretely, the harness is the scaffolding that does the unglamorous, decisive work: it gathers the right cross-file context before the model reasons, it routes a finding through the appropriate depth of analysis, it runs a separate evaluation of any proposed fix for safety and correctness before a human ever sees it, and it records the outcome. A purpose-built remediation pipeline, for example, leans on 120-plus deterministic codemods for well-understood fixes and spends model compute only where a fix genuinely requires it, with a dedicated Fix Evaluation Agent checking the result against safety, effectiveness, and cleanliness before anything is proposed. The harness is also where breadth lives without diluting depth: a shared cross-file context gatherer feeds both triage and remediation, and a single platform spans twelve native scanner integrations through universal SARIF, deployed in the cloud, self-hosted, or air-gapped with a self-hosted model.
This is the applied layer of context engineering. The context graph beneath it is the data structure; the harness is what engineers the context in and out of that structure at each step. Stretch the aperture wide enough and the whole thing has an industry name now, agentic security engineering, a platform of purpose-built AI agents doing security work across the lifecycle. But the name is the destination, not the entry point. The entry point is the discipline. For a closer look at securing that scaffolding itself, see our work on the AI coding harness.
What good context engineering looks like
Across both prongs and the harness that runs them, a few principles separate engineered context from a model with a long prompt.
Calibration over volume. The "lost in the middle" and length-degradation findings are not edge cases. The goal is the right tokens, placed and pruned deliberately, not the most tokens. Good context engineering spends compute where a decision earns it and uses deterministic logic where it does not.
Provenance and auditability. A security decision a team cannot explain is a decision it cannot defend at audit. Engineered context carries its evidence: why a finding was suppressed, what dataflow supports a verdict, what convention shaped a fix. Decisions become records, not guesses.
Validation as a separate step. Generation and judgment should not be the same pass. A fix proposed by one process and proven by another is the difference between a suggestion and something safe to merge.
Accumulation that compounds. This is the property generic AI does not have. A context-engineered system gets better with use because it keeps the decisions an organization makes. In practice, on day one that compounding rests on what is concretely available: a project policy file that encodes your rules, caches of generated analyzers and prior classifications that make repeated work cheaper and more consistent, and the recorded dispositions of past triage. From there the system reflects more of your team's patterns and preferences the longer it runs, so the same false positive is not re-investigated every quarter and a rejected fix shape is not proposed again. The honest version of this curve matters: the first layer, exploitability suppression, pays off within hours, while the deeper organizational fit accrues over months of use. That is the opposite of a generic model, which performs the same in month twelve as it did on day one. For the underlying mechanism, see how context fixes compound on a context graph.
Why context is the moat
Put the pieces together and the strategic point is plain. Models are converging and will keep converging. The context about your code, your conventions, your past decisions, and your design intent is yours alone, and it grows more valuable the more your organization uses the system. You cannot outwork machine-speed vulnerability discovery, and you cannot out-model a competitor who has the same frontier API you do. The durable advantage is the context you have engineered and the harness that puts it to work, going in and coming out, on one shared foundation. For the full economic case, our analysis of the cost asymmetry behind context-aware remediation walks the numbers.
Context engineering is easiest to judge on code you already know. A Pixee proof of concept runs context-aware triage and remediation against your own repositories, so you can see for yourself which findings it suppresses and which fixes it proposes in your conventions. See it on your codebase.
Go deeper
Context engineering for security is a discipline, and this page is the map. The detailed work lives in the cluster:
• Why AI code fixes fail without context. The failure modes, and the engineered context chain that prevents them.
• From detection to decision: context graphs in AppSec. The data structure beneath the discipline, and why decision traces matter.
• Machine-speed triage and context intelligence. Context applied to the triage bottleneck.
• VulnOps: the operating model for reactive security. Triage and remediation as a continuous function.
Frequently asked questions
What is context engineering for security? It is the discipline of systematically assembling, calibrating, and validating the information an AI needs to make correct security decisions across the software lifecycle, from design-stage review to triage and remediation. It treats "what the model sees" as the core engineering problem rather than which model is used.
How is context engineering different from prompt engineering? Prompt engineering is about writing the instructions you give a model. Context engineering is the broader discipline of managing the entire set of information the model sees during inference, including tools, retrieved data, memory of past decisions, and history. Prompt engineering is a subset of context engineering.
Is context engineering the same as RAG? No. RAG (retrieval-augmented generation) is one technique for pulling external information into the model's context at query time. Context engineering is the wider practice that decides what to retrieve, what else to include, how to order and prune it, and how to validate the result. RAG is a tactic within context engineering.
Is a context graph the same as context engineering? No. A context graph is a data structure for storing relationships between code, findings, and decisions. Context engineering is the discipline of deciding what goes into that structure, what to retrieve from it and when, and how to prove the decision was correct. The graph is plumbing; the engineering is judgment.
Is context engineering for security about protecting the AI's context window? Not here. Some writing uses "context engineering security" to mean defending the context window against prompt injection or data poisoning, which is a real concern. This page uses the phrase in the other direction: engineering the right context so an AI makes correct application-security decisions like triage and remediation. The two are complementary but distinct.
Where in the software lifecycle does context engineering apply? Both ends. Going in, at the design stage, it reasons about intent and architecture to catch risk before code exists. Coming out, it powers context-aware triage and remediation on the code and findings that do exist. The same accumulating context serves both.
Why do AI security fixes need context at all? Because the same model performs very differently with and without it. In one controlled study, injected security and code context lifted a model's buffer-overflow repair rate from 15% to 63%. Detection is not repair, and context is what closes the gap.