The Hidden Tax of AI Coding Tools


Your engineering team shipped 40% more code last quarter. Your AppSec team didn't grow by a single headcount.
Somewhere between those two facts lives a problem nobody names until it shows up in an audit finding or a breach disclosure.
AI coding assistants are delivering on their promise. Developers write code faster, complete tasks sooner, and push more pull requests per sprint. The productivity gains are real and measurable. No reasonable person argues against adopting them.
But every line of AI-generated code feeds the same scanner pipeline your security team was already drowning in. And that pipeline has three failure points that compound with every new Copilot seat you provision:
Each one is manageable in isolation. Together, they create a capacity crisis you won't see until the math has already stopped working.
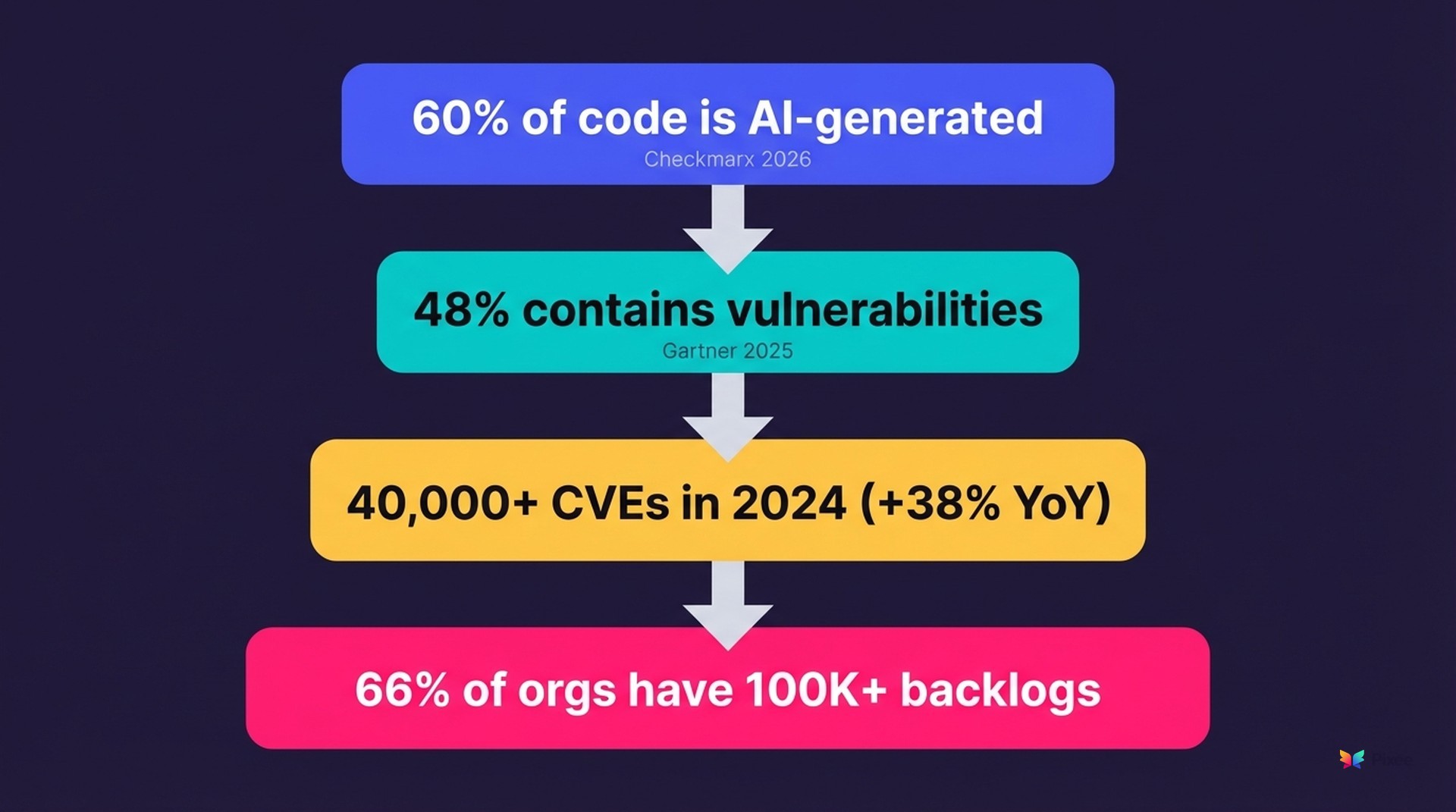
AI Code Multiplies Scanner Findings
The volume story starts with a number that should bother anyone running an AppSec program.
of organizations now say more than 60% of their code is AI-generated.
— Checkmarx Future of AppSec 2026
At some companies, that figure hits 64% (JFrog Software Supply Chain Report 2025).
That code isn't clean. Gartner's Magic Quadrant for Application Security Testing (2025) found that 48% of AI-generated code contains security vulnerabilities. Nearly half of all AI-assisted output ships with exploitable flaws.
The problem spans models and tools. Five independent studies, from CodeRabbit, OX Security, Veracode, Checkmarx, and Black Duck, converge on a consistent finding:
AI-assisted pull requests carry 2.74x more cross-site scripting vulnerabilities and 68% more defects than human-only code.
Not one outlier study. A research consensus forming across the security industry.
The compound math
Run this on a 1,500-person engineering org:
The increase compounds. More AI-generated code produces more findings, which extend triage queues, which slow remediation, which grows the backlog.
And the backlog was already unmanageable. 66% of organizations report backlogs exceeding 100,000 vulnerabilities.
The uncomfortable arithmetic: your developers got faster, your codebase got bigger, your scanner findings multiplied, and your security team's capacity stayed exactly the same.
More Findings Break Your Team Before They Break Your Code
This is where the hidden tax actually lands. Not in the codebase, but in the humans responsible for sorting through what the scanners produce.
of security alerts are false positives.
— Black Duck Global DevSecOps 2025; JFrog Software Supply Chain Report 2025
JFrog's analysis went deeper: 88% of vulnerabilities rated "Critical" by CVSS scoring weren't actually critical in deployment context. The severity labels your team triages against are wrong nine times out of ten.
What follows is predictable.
One security engineer at a large retailer described the math plainly:
"I'm a team of, like, 14 people. There's 500 developers. We can't do technical reviews of everyone."
At that ratio (roughly 1 security engineer per 35 developers) manual triage at AI-accelerated code volumes is structurally impossible.
Where the pain actually lives
In analysis of 395 conversations across 102 companies, we found triage pain mentioned 2.4x more frequently than remediation pain (126 instances vs. 52).
The market talks about fixing. Buyers talk about sorting. There's a gap between what vendors sell and what actually costs $1.88M per year in senior engineer labor.
Aikido's State of AI Security in Development report (2026) quantified the individual toll:
What happens when teams can't keep up
They stop trying.
22% of teams have disabled security tooling entirely because false positive overload made the tools unusable (Aikido 2026).
At one major bank, the triage burden got so severe that "60-70% of true positives were marked as false positive." Real vulnerabilities dismissed as noise because the team couldn't distinguish signal from static.
A head of AppSec at a telecommunications company captured the confidence crisis:
"How are you coming up with the confidence rate? How do you know? Because you don't know how the application uses it."
When scanners can't prove exploitability, every finding requires manual investigation. At AI-accelerated volumes, that investigation simply doesn't happen.
The cascade beyond security
Alert fatigue reaches beyond the security team.
A developer at a major streaming platform described their frustration with SAST tooling:
"We weren't very impressed with the results. The volume of false positives, or things that didn't have reachability analysis to see if the vulnerability can actually be triggered."
When developers lose confidence in scanner output, they stop engaging with security findings altogether. Failed tools, as one banking security leader put it, have "poisoned the well."
Multiple CISOs expressed the same sentiment:
"We need help fixing problems, not finding me anything else."
Detection is saturated. The average team runs 5.3 scanning tools. None of them fix anything at scale.
What's left is a backlog that grows faster than any team can process it. As one AppSec leader at a multinational bank put it:
"2,000 low fidelity things vs. 50 high fidelity."
The 50 are what matter. The 2,000 are what consume the calendar. A systematic triage framework can reduce those 2,000 alerts to the 50 that actually warrant action, but most teams are still sorting by hand.
Regulators Won't Wait for Your Backlog
— Veracode State of Software Security 2025
That number was already unsustainable before AI coding tools accelerated the volume of findings feeding the queue.
Now overlay the regulatory timeline:
If your organization takes 252 days to fix half its known vulnerabilities, you cannot comply with regulations that measure response windows in hours and days. Basic calendar math.
The 48-hour window
Google Cloud's Threat Horizons report (H1 2026) adds another dimension. The window between CVE disclosure and mass exploitation has collapsed from weeks to 48 hours.
That's observed behavior, not a theoretical attack timeline. Attackers run automated exploit pipelines against newly disclosed CVEs while your team is still evaluating whether the finding applies to your environment.
A new CVE is disclosed on Monday. By Wednesday, mass exploitation is underway. Your team is still eight months from fixing half the backlog.
The gap between attacker speed and defender response time is widening. AI-generated code volumes accelerate it.
Compliance friction compounds the problem
For regulated enterprises, data sovereignty requirements and governance mandates already limit which AI tools can touch production code. Add compliance deadlines measured in hours to remediation cycles measured in months, and you have a structural gap that headcount alone cannot close.
One CISO at a major financial services firm described the internal friction:
"The part where we have to approve the remediation...is manual. I continue to highlight within the team that there is just lack of process."
That bottleneck is operational, not technical. Approval workflows designed for a dozen findings per quarter now face thousands per month.
Another VP of Security described the procurement process itself as a compliance bottleneck:
"It took us four months to get here. We had a big AI Committee, and it was all internal stuff."
Four months of governance review before a security tool could even be evaluated. The vulnerability backlog grew every sprint.
The audit forcing function
One audit scenario concentrates minds fastest: "Fix 7,600 findings before the re-audit."
That's not a planning exercise. That's a 30-60 day sprint with regulatory consequences.
If your remediation pipeline depends on manual developer effort at 6 hours per fix:
What Changes When the Bottleneck Breaks
The organizations making progress on this problem share a common pattern: they stopped treating triage and remediation as separate manual workflows and started treating them as a single automated pipeline.
1. Eliminate noise through exploitability analysis
Instead of flagging every potential vulnerability and asking a human to determine context, automated analysis evaluates whether a finding is actually reachable and exploitable in the specific application's deployment context:
These aren't questions you can answer with regex or CVSS scores. They require understanding the application's actual runtime behavior.
This is how you go from 2,000 findings to 50. Not by ignoring risk, but by proving which risks are real. The 1,950 findings you eliminate aren't false negatives. They were never exploitable in the first place.
2. Generate fixes that match existing code conventions
Most automation attempts fail here. The failure modes are instructive.
An engineering leader at a large financial exchange described their first attempt at automated remediation:
"We did the automated PRs...and it actually created so many PRs that it crashed our build servers."
Volume-first automation without contextual filtering doesn't reduce burden. It redistributes it from the security team to the build infrastructure.
A CISO at a wealth management firm evaluated a vendor's automated fix capability and summarized the result:
"Fixes were terrible."
The tool was vendor-locked to a single scanner's findings and generated fixes that developers wouldn't merge. After that experience, the CISO's first question for any new tool was how it differed from generic AI approaches. What resonated was a simple framing: "Narrow but deep and higher quality."
An engineering leader at a major enterprise saw a similar pattern with their existing SCA investment: vulnerability counts for their most expensive category stayed "pretty flat" after implementation. The tool found things. It didn't fix them. Finding without fixing is just a more expensive way to grow the backlog.
A VP of Engineering at a mid-market manufacturer framed the standard more precisely:
"For the team, the most valuable resource we have is attention."
Any fix that requires developer review time to understand, validate, and rework is borrowing against the same scarce resource the automation was supposed to protect.
Purpose-built vs. generic: the numbers
In our triage and remediation platform, we observe a 76% merge rate across thousands of pull requests. Developers accept three out of four automated fixes without modification.
Generic AI remediation tools typically achieve below 20%.
The difference is constraint, not sophistication. Purpose-built fix generation evaluates each fix against the application's existing patterns and test suite before presenting it to a developer.
~$39 per resolved vulnerability
A developer at a major Canadian bank reinforced this from the receiving end:
"Anything that can help them eliminate vulnerabilities is gonna be beneficial."
Developers aren't opposed to automated fixes. They're opposed to bad automated fixes that waste their review time. The merge rate is the trust signal: not how many fixes are generated, but how many developers actually ship.
The scale of what's at stake
A developer at a major bank told us that fixing a single SQL injection manually takes roughly 6 hours. Multiply that across a backlog of thousands, and the aggregate cost (as one CISO described it) is measured in "developer centuries of time."
An engineering manager at a security consultancy put it in budget terms:
"If you can fix 1,000 vulnerabilities for me, I will happily pay you $100,000. Totally worth that much money for me."
At $39 per fix, that math works. At $180 per fix with a 20% acceptance rate, it doesn't.
3. Keep humans in the loop
The organizations where 81% knowingly ship vulnerable code aren't staffed by negligent people. They're staffed by capable engineers who can only address 32% of known vulnerabilities given current capacity constraints.
Automation that replaces developer judgment fails. Automation that presents validated fixes as pull requests for developer review, letting the engineer decide, succeeds at rates that actually move the backlog.
Three Questions for Your Next Planning Meeting
AI coding tool adoption is accelerating. The security capacity gap it creates will not resolve through hiring. The ratio of security engineers to developers has been stuck at roughly 1:35 for years, and there aren't enough AppSec engineers in the pipeline to change it.
If your organization is expanding Copilot seats, these are the questions worth asking before the next planning cycle:
1. What's your finding-to-capacity ratio, and how did it change after AI coding tool adoption?
If your security team's workload grew proportionally to your developers' output increase, that ratio deteriorated. It will keep deteriorating with every new seat.
2. What percentage of your scanner findings are confirmed exploitable vs. noise?
If you can't answer this precisely, your team is spending triage time on findings that don't matter. The 71-88% false positive rate is your team's daily reality.
3. If a regulator asked for your MTTR today, what number would you report?
If the answer is anywhere near the industry median of 252 days, you have a compliance exposure that gets worse every quarter AI-generated code volumes increase.
Your AI coding tools aren't the problem. The security capacity debt they expose is.
That debt compounds silently. More findings per sprint, fewer investigated per quarter, longer remediation cycles per year. It surfaces as a failed audit, a preventable breach, or a team that quietly stops investigating alerts altogether.
The organizations that avoid this outcome aren't the ones with the biggest security teams. They're the ones that recognized the capacity gap before it became a crisis and built the pipeline to close it.
Related Reading
weekly tracking of AI code security flaws
AI writes code faster than teams can secure it
context engineering addresses the hidden tax